tech life love
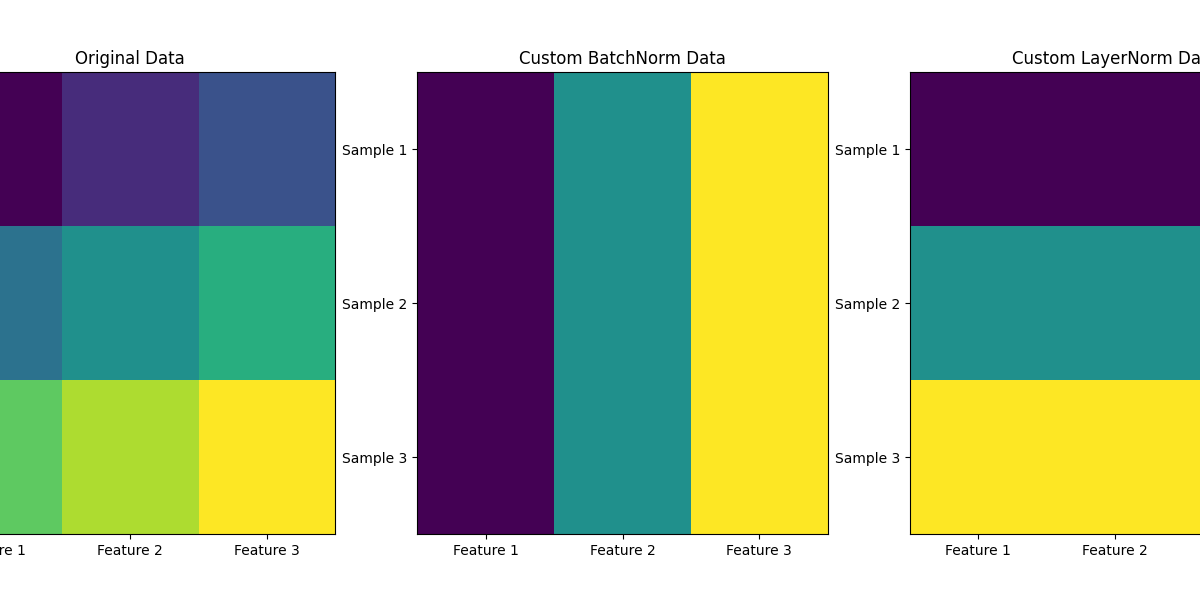
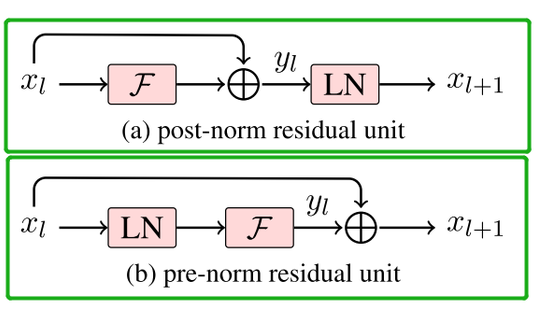
可以说,如果没有残差连接和 Layer Normalization(层归一化)这样一刚一柔的黄金组合...
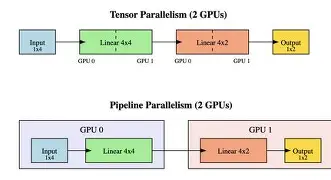
写在前面 在上一篇文章中,我们讨论了如何用数据并行、张量并行和流水线并行,把一个大模型“拆开”放到成...
写在前面 目前为止的文章都在聊一件事:单个模型内部的“微观世界” ——Embedding怎么工作、A...
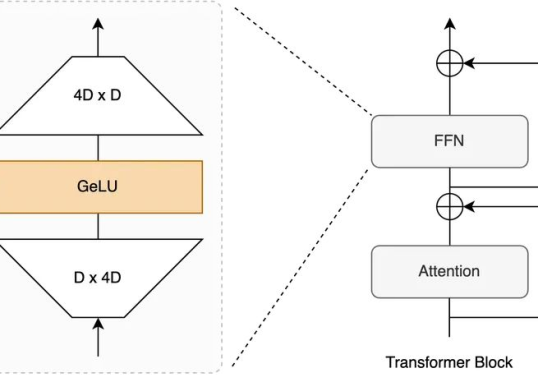
如果说我们之前拆解的所有Transformer组件——从FFN到Attention——都是为了让单个...
写在前面 在前面的六篇文章中,我们完整拆解了Transformer的静态架构——从Tokenizer...
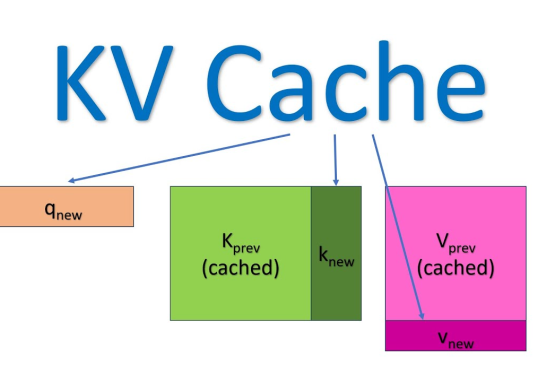
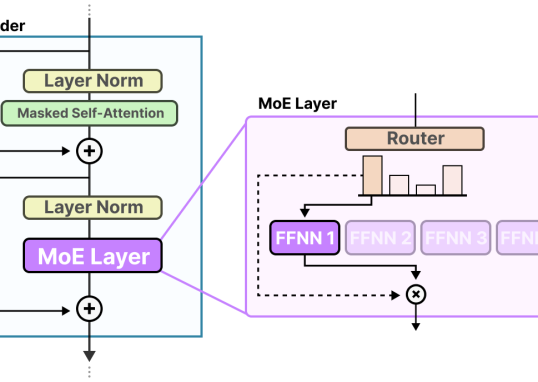
写在前面 在前几篇文章中,我们像拆解一个精密的机械表一样,一步步解剖了 LLM 的各个核心组件:从 ...
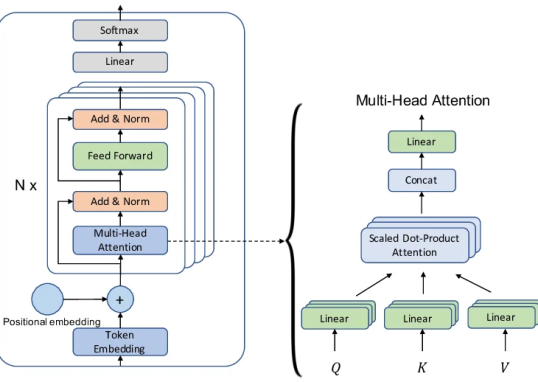
写在前面 终于,我们来到了 Transformer 最核心、最“灵魂”的部分——Attention(...
写在前面 在之前的系列文章中,我们从 Tokenizer 讲到 Embedding 再到 RoPE,...
一篇关于 RAG 的学习笔记:RAG 不是把向量数据库接到模型前面那么简单,而是一条从知识组织、召回...
写在前面 在前两篇文章中,我们分别拆解了 LLM 的整体架构,又专门深挖了 Tokenizer。现在...