写在前面
在前几篇文章中,我们像拆解一个精密的机械表一样,一步步解剖了 LLM 的各个核心组件:从 Tokenizer 到 Embedding,从 Attention 到 FFN。我们看着数据在模型中游走,Token 之间不断交流,知识被一层层加工。
但这个流程中有一个共同点:每个核心模块(Attention 和 FFN)都被一层“神奇的光环”所包裹,这光环就是残差连接与层归一化。它们不创造新的内容,也不改变信息的方向,只是默默地在幕后工作,维持着模型这个庞然大物的稳定。
然而,就是这样一个看似微小、通常只需几行代码定义的组件,其位置选择——应该放在哪里?——却在过去几年里引发了大规模的“架构之争”。这直接决定了我们能否让 Transformer 从几十层,稳定地扩展到数百甚至上千层。
今天,我们将揭开这层面纱,深入探讨残差连接的精妙之处,重走 Pre-Norm 与 Post-Norm 的“恩怨情仇”,并一同展望最新的归一化策略如何突破极限。
一、残差连接:为深层网络劈开的“绿色通道”
1.1 为何“深”却成了问题?
在深度学习的早期,一个直观的想法是:网络越深,能力越强。但实践却给了研究者们一记重击。
在没有残差连接的传统网络(如 VGG)中,当网络层数超过 20 层时,研究者们观察到了一个奇特的现象:不仅测试集的错误率上升,连训练集的错误率也同步升高。这不是过拟合,而是 “网络退化” 问题。
简单来说,深层网络的优化难度随层数增加呈指数级增长。梯度在反向传播时,经过层层传递,就像传话游戏里的信息,要么逐渐微弱到消失(梯度消失),要么被不合理地放大到失真(梯度爆炸)。最终,浅层的权重几乎无法更新,网络的潜力被深度本身扼杀了。
1.2 “高速公路”的诞生
残差连接(Residual Connection)的提出,正是为了解决这一难题。它的核心思想异常简洁:在网络的输入和输出之间,建立一条“跳跃连接”(Shortcut Connection) ,让信息可以绕过中间的变换层,直接传递。
用公式表示,一个标准的残差块可以写为:
[
y = x + F(x)
]
这里,(x) 是原始的输入,(F(x)) 是子层要学习的“残差函数”。
这个设计画龙点睛之笔在于:它重构了网络的学习目标。 在过去,网络需要费力地学习一个完整的映射 (H(x))。现在,它只需要学习输入与输出之间的“变化量” (F(x) = H(x) – x)。学习恒等映射(即输出等于输入)变得异常简单:只需将 (F(x)) 逼向零即可。
于是,梯度多了一条从深层流向浅层的“高速公路”。即使主路径上的梯度衰减了,残差连接也能保证浅层至少得到一个保底的梯度信号,从而避免了梯度消失,让训练上百层、上千层的网络成为可能。没有它,我们所讨论的“大模型”将不复存在。
二、Normalization:给梯度戴上“稳定器”
如果说残差连接是信息高速公路,那归一化(Normalization)就是路上的“交通规则”。
当信息在高速公路上奔驰时,每一层网络的权重计算,都可能导致数据的分布发生剧烈变化。上一层的输出,经过矩阵乘法后,可能会变得“面目全非”,尺度飘忽不定。这种现象在几百上千层的巨型网络里会迅速恶化,导致整个模型数值溢出,训练崩溃。
层归一化(Layer Normalization, LN)的作用,便是在每一个残差块的内部,对输出进行一次“标准化”。它会将数据拉回到一个均值为 0、方差为 1 的稳定分布,从而确保梯度流在任何时候都处于一个健康合理的区间。
现代 LLM 则更偏爱使用 RMSNorm(Root Mean Square Normalization) 。它是 LayerNorm 的精简版,去掉了计算均值的步骤,只保留对数据的“尺度”进行约束:
[
\text{RMSNorm}(x) = \frac{x}{\text{RMS}(x)} \cdot \gamma
]
别小看这个“偷懒”的操作。它换来的,是更少的计算量和更快的推理速度,而在模型最终效果上,和 LayerNorm 几乎不相上下。这正是 LLaMA、Qwen、DeepSeek 等一线模型都采用它的原因。
三、Post-Norm vs Pre-Norm:百年“站位”之争
归一化和残差连接这对黄金搭档,它们之间微妙的空间关系,却引发了 Transformer 架构史上最著名的一场“站位”之争。
3.1 原教旨主义:Post-Norm 的结构
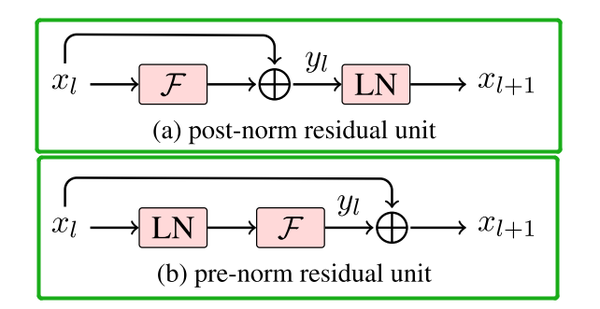
最原始的 Transformer 论文《Attention Is All You Need》里,采用的是 Post-Norm(后归一化) 结构。
它的计算顺序是:子层(Attention/FFN)→ 残差连接 → 层归一化。
用代码伪代码来体现,这就是经典的 Post-Norm Block:
# Post-Norm
def post_norm_block(x):
# 1. 先计算子层 (Attention 或 FFN)
sub_output = sub_layer(x)
# 2. 再与输入残差相加
x = x + sub_output
# 3. 最后进行归一化
x = layer_norm(x)
return x从“语义”上讲,这种设计非常自然。网络块处理信息,然后将新旧信息融合,最后把融合后的结果标准化,再交给下一块处理。万物有序,符合直觉。
3.2 “死亡”真相:Post-Norm 为何不可深?
然而,一旦将 Post-Norm 的网络堆叠到几十层以上,麻烦就来了。训练变得极不稳定,模型在启动阶段极易“爆炸”或者“跑飞”,这种现象在当时几乎是无解的。于是,研究者不得不引入各种复杂的“拐杖”:比如复杂的学习率预热(warm-up)策略,让学习率从极小的值开始缓慢增加,来“哄着”网络度过最初的危险期。
经过理论分析,背后的原因浮出水面:Post-Norm 结构下,靠近输出端的层的参数,其梯度在训练初期惊人地大。一旦学习率稍有不慎,梯度就会像洪水一样冲垮整个模型的优化。层数越深,这种现象越严重,直接把大规模深度训练的路堵死了。
3.3 实用主义胜出:Pre-Norm 的崛起
为了解决 Post-Norm 的不稳定问题,研究者们微调了 LN 的位置,提出 Pre-Norm(前归一化) 结构。
计算顺序变为:层归一化 → 子层(Attention/FFN)→ 残差连接。
用代码来表示:
# Pre-Norm
def pre_norm_block(x):
# 1. 先对输入进行归一化
x_norm = layer_norm(x)
# 2. 再计算子层
sub_output = sub_layer(x_norm)
# 3. 最后进行残差连接
x = x + sub_output
return x这个小小的顺序调整,带来的是训练稳定性的质的飞跃。研究证明,Pre-Norm 能天然地让整个网络的梯度分布更加平滑,即使在训练初期也不需要小心翼翼的学习率预热。一句话概括,它让训练深层网络从“走钢丝”变成了“开高速”。
该设计很快受到工业界和学术界的狂热采纳,迅速成为了 GPT 系列、LLaMA 系列等几乎所有主流大模型的默认架构。
3.4 新旧阵营一览
| 归一化位置 | 代表模型 | 优点 | 缺点 |
|---|---|---|---|
| Post-Norm | BERT, RoBERTa, ALBERT | 同等规模下,模型最终上限可能更高 | 训练极不稳定,无法深度扩展 |
| Pre-Norm | GPT, LLaMA, PaLM, Qwen | 训练极其稳定,可轻松扩展至千亿参数 | 深层网络可能存在表征坍缩风险 |
3.5 Pre-Norm 的“阿喀琉斯之踵”
Pre-Norm 虽然赢了,但并非完美。
最新研究发现,Pre-Norm 有一个潜在的代价:它可能会导致深层 Transformer 出现 “表征坍缩”(Representation Collapse) 。通俗讲,网络层数太多时,不同 Token 之间的差异性经过几十上百次 Pre-Norm 标准化后,可能被“磨平”了。深层似乎失去了足够的区分度,所有东西都趋同了,阻碍了模型通过增加深度来进一步提升性能。
这也就是为什么最终人们发现,LaaS 的一些极其深的 Pre-Norm 模型,其性能无法持续线性增强,甚至会出现边际效益递减。
四、突破边界:为了追求极致而登场的“新星”们
Pre-Norm 和 Post-Norm 各有优劣,科研人员自然不会止步于“二选一”。他们开始通过各种精妙的设计,尝试“既要又要”:既要 Pre-Norm 的稳定,又要 Post-Norm 的性能。
4.1 DeepNorm:微软将Transformer推到1000层的秘密武器
2022 年,微软研究院团队带着他们的 DeepNorm 震撼了学术界。他们提出的口号简单直接:让 Post-Norm 也可以稳定训练到上千层。
DeepNorm 的思路很巧妙,它认为 Post-Norm 的不稳定源于模型更新深度(model update)随着网络加深而失控。因此,它在不改变归一化位置的前提下,在两个地方动了手脚:
- 在残差连接上加了一个缩放因子 (\alpha > 1):
x = LayerNorm(α * x + sub_layer(x)),对原始输入的信号进行了“提权”处理。 - 在初始化阶段缩小特定参数的初始值:比如在 Xavier 初始化后,额外乘上一个缩放因子 (\beta < 1),让模型一开始的行为更“温顺”。
这一大一小的因子,联手将模型更新牢牢束缚在了一个可控范围内,无论网络深浅。从性能上看,微软用 32 亿参数的 200 层 DeepNet,在翻译任务上击败了 120 亿参数的 48 层最优模型,强力证明了通过提升深度能够挖掘出极强的潜力。
4.2 各路英豪:取长补短的策略
DeepNorm 证明了“用 Post-Norm 之魂 + 额外稳定术”是可以驯服极深网络的,但它的根基仍然是 Post-Norm,结构本质上还是单一路径。于是,更具颠覆性的结构改进涌现出来。
- Mix-LN:分层治理:2024 年底提出的 Mix-LN 认为,既然 Pre-LN 在浅层好用、Post-LN 在深层潜力大,那何不按照层数动态分配?于是,它将前几层设为 Post-LN 以保持深层梯度,后几层设为 Pre-LN 以保证整体稳定。这种方法几乎零成本提升了模型潜能,让新旧结合的优势得以释放。
- HybridNorm:区块自治:2025 年的 HybridNorm 做得更“绝”,它将策略精细到了块级别。它采用 QKV 归一化 + FFN 的 Post-Norm 混合架构。此举既稳住了自注意力的学习动态,又充分发挥了 FFN 在深度学习中的潜能,显示了在大型稀疏和稠密模型中均能全面超越 Pre/Post-LN 的实力。
- Keel:Post-LN 的“重生”:如果 DeepNorm 只是“技术修车”,那字节跳动团队 2026 年的 Keel 便是直接给它“换了发动机”。Keel 核心诊断出“原罪”在于 ResNet 式的残差路径会导致深层梯度消失。因此,它直接替换为 Highway 风格连接,让梯度不受阻碍地贯穿网络。效果出奇惊人:超过 1000 层的稳定训练成为可能,且性能随时延展而持续放大。这给了业界一个强烈的信号:深度 Scaling 的时代,也许才刚拉开帷幕。
- ResiDual:双路径保险:既然 Pre 和 Post 各有好坏,为什么只能做单选题?微软 2023 年的 ResiDual 勇敢打破常规,通过 Pre-Post-LN (PPLN) 双重残差连接 将两者缝合在一起。从数据路径上,这就像同时买了两种保险,确保既不会出现梯度消失,也不会向表征坍缩退化,在实际翻译任务上也显著更优。
- SiameseNorm:双胞胎网络:2026 年 2 月 ArXiv 发表的 SiameseNorm(归一化连体婴) ,堪称解决这一难题的最大胆设计。它不单是“双路径”,而是直接造了一对 Pre-Norm 流和 Post-Norm 流的双胞胎网络(Siamese) ,并让两者共享参数,同步流动后合并梯度。这一设计打破了必须取舍单一路径的魔咒,将“既要又要”变成了天然的并集。在 13 亿参数规模实验中,SiameseNorm 展现出了极强的鲁棒性。
- SpanNorm:跨块之桥:紧接着,2026 年初 ArXiv 上的 SpanNorm 又提供了一种新思路。它放弃了传统残差只跨子层的模式,彻底建立了一条跨越整个 Transformer 块的干净残差连接,并在大终点使用了 PostNorm 式聚合归一化。一种大一统的整合优势叠加,在理论上保证了跨深度信号的无损传递,并对表征坍缩通病提出了缓解方案。
五、总结与展望:从“站位”到“融合”
至此,我们可以清晰地看到一条技术演进的主线。
| 阶段 | 代表方案 | 核心思想 | 解决的问题 | 引入的新挑战 | 发布时间约 |
|---|---|---|---|---|---|
| 1. 原始时代 | Post-Norm | LN 放在残差求和后 | 定义了 Transformer 经典结构 | 深层训练不稳定,极度依赖学习率预热 | 2017 |
| 2. 稳定时代 | Pre-Norm | LN 放在子层前、残差求和前 | 极致的训练稳定性,实现轻松深度扩展 | 深层出现表征坍缩,深度收益受限 | 2019-2020 |
| 3. 深度时代 | DeepNorm | 残差侧缩放 + 初始化稀疏化 | 首次让极深(千层)模型能稳定训练 | 调参复杂,工程实现稍显繁琐 | 2022 |
| 4. 融合时代 | Mix-LN, HybridNorm, Keel, ResiDual, SiameseNorm, SpanNorm | Pre/Post 体系混合,或重构残差连接 | 统一极深网络的训练效率与性能表现 | 新范式仍在探索,工程框架尚待成熟适配 | 2023-2026 |
回望过去,残差连接与归一化这对老搭档,最开始只是一个简单的数学公式。为了追求更深、更强大的模型,无数研究者不得不回过头来,对这一公式进行细致的调整和革新。
我们经历了一开始的“经验直觉”(Post-Norm),转向了“稳扎稳打”(Pre-Norm),看过了通过参数调节实现“无上突破”(DeepNorm),如今正在加速进击“全能整体”(Hybrid/ResiDual/SiameseNorm)。
这不仅是一次技术迭代,更是一次设计理念的转变。我们不再把残差连接和归一化看作静态、孤立的部件,而开始把它们当作一个动态的、需要与其它组件协作的系统。也许,在未来,这种摆放位置将不再是需要纠结的“固定设计”,而会成为神经网络 “自适应学习” 的一部分。
作者
884705373@qq.com
相关文章