写在前面
在之前的系列文章中,我们从 Tokenizer 讲到 Embedding 再到 RoPE,已经走完了数据从“人类语言”到“模型可计算的向量”的完整路程。现在,我们来到了 LLM 最“厚重”的部分——FFN(Feed-Forward Network,前馈神经网络) 。
为什么说它“厚重”?因为在一层 Transformer Block 中,Attention 负责让 Token 之间相互“交流”,而 FFN 才是真正存储和处理知识的场所。如果把 Transformer 比作一个工厂,Attention 是流水线上的“调配工人”,FFN 则是一台台“加工机器”——绝大部分的“生产设备”都在这里。
FFN 的参数量通常占据整个模型参数的 2/3 左右。也就是说,当下载一个 7B 的模型,其中大约有 4.5B 的参数都躺在 FFN 里。理解 FFN,就是理解 LLM 的“记忆”和“思考”是怎么发生的。
一、FFN 在 Transformer 中的定位
1.1 Transformer Block 的“双引擎”
每一个标准的 Transformer Block 都由两个核心模块组成:
输入 x
↓
Pre-Norm → Attention → 残差连接(x + Attention(x))
↓
Pre-Norm → FFN → 残差连接(x + FFN(x))
↓
输出Attention 让序列中的 Token 互相“看到”对方,完成信息的融合和交互。但 Attention 本身是线性变换 + 加权求和——本质上还是线性的。如果没有 FFN,再多的 Attention 层叠加起来也只是一个复杂的线性模型,表达能力严重受限。
FFN 的作用就是引入非线性,让模型能够拟合更复杂的函数,从而存储和处理更丰富的知识。
1.2 FFN 为什么能“存储知识”?
一个有趣的观察是:在 LLM 中,Attention 层更多负责“提取”和“整合”上下文信息,而事实性知识和推理规则主要存储在 FFN 的参数中。
这背后的直观理解是:Attention 的权重矩阵(Q、K、V)负责“对谁感兴趣”,它们决定了信息在 Token 之间的流动路径;而 FFN 的权重矩阵(W1、W2)则像一个巨大的“键值对存储器”,将输入模式映射到输出模式。研究表明,Transformer 中的 FFN 层可以被视为某种形式的键值记忆网络——第一层权重矩阵充当“键”,第二层充当“值”,将输入的语义模式转换为特定的输出。
这也解释了为什么 FFN 的参数量如此巨大:要存储海量的世界知识和语言规则,需要足够大的“记忆空间”。
二、从 ReLU 到 SwiGLU:FFN 激活函数的演进
如果说 FFN 的矩阵乘法是模型的“骨架”,那么激活函数就是赋予其“生命力”的关键。它的选择直接影响模型的表达能力、训练稳定性和收敛速度。过去几年,FFN 激活函数的演进经历了三个重要阶段。
2.1 第一阶段:ReLU 的简单时代
早期 Transformer(如 2017 年原版论文)使用的是最简单的 ReLU 激活函数:
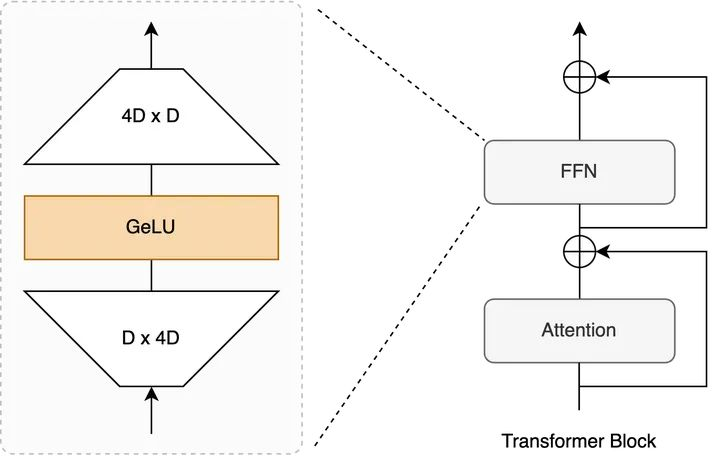
ReLU(x) = max(0, x)标准 FFN 的结构为:
FFN(x) = W2 · ReLU(W1 · x)其中,W1 将输入从 d_model 维度映射到 d_ffn(通常为 d_model 的 4 倍),W2 再映射回 d_model。
ReLU 的优势非常明显:计算简单,梯度不饱和。但它有一个著名的缺陷——“Dead ReLU”问题:当输入小于 0 时,ReLU 的输出为 0,梯度也为 0。一旦某个神经元“死掉”,它可能永远无法恢复,造成模型容量的永久损失。这种硬零边界在深层网络中尤为致命。
2.2 第二阶段:GELU 的平滑替代
为了解决 ReLU 的“死亡”问题,研究者们引入了 GELU(Gaussian Error Linear Unit) ,BERT 系列模型就是它的著名使用者。
GELU(x) = x · Φ(x)其中 Φ(x) 是标准正态分布的累积分布函数。直观理解:GELU 不是硬性地把负值截断为 0,而是根据 x 落在正态分布中的概率来决定“放多少信息过去”——有点像一个“概率门”。
GELU 在实践中通常使用一个近似公式以提高计算效率:
GELU(x) ≈ 0.5x · (1 + tanh(√(2/π) · (x + 0.044715·x³)))GELU 在负值区域保留了平滑的非零输出,显著缓解了 Dead ReLU 问题。但它仍然只是一个逐元素的非线性变换——对每个神经元“一视同仁”地应用同一个函数曲线,没有考虑到不同特征之间的交互。
2.3 第三阶段:GLU 家族与门控革命
真正改变游戏规则的,是门控线性单元(Gated Linear Unit, GLU) 的引入。
GLU 的核心思想是:让模型自己学习“哪些信息可以通过” ,而不是用一个固定的函数一刀切。GLU 将输入分成两路:
GLU(x) = (x · W1 + b1) ⊙ σ(x · W2 + b2)其中:
- 值路(Value Path):
x · W1 + b1承载实际的信息内容 - 门路(Gate Path):
x · W2 + b2经过 Sigmoid 激活,输出 0 到 1 之间的“门控信号” ⊙表示逐元素乘法——门控信号决定了值路中的每个维度有多少能通过
这种设计让 FFN 拥有了动态的、数据依赖的信息路由能力。不是所有输入都走同一条路径,而是根据输入本身来决定信息流的“开关”和“强度”。
GLU 的成功催生了一系列变体。Noam Shazeer 在论文《GLU Variants Improve Transformer》中系统对比了多种门控激活函数:
| 变体 | 门路激活函数 | 特点 |
|---|---|---|
| GLU | Sigmoid | 原始版本,门控值在 0~1 之间 |
| ReGLU | ReLU | 计算简单,但仍有硬零边界 |
| GEGLU | GELU | 平滑门控,效果优于 ReGLU |
| SwiGLU | Swish/SiLU | 最终胜出的方案 |
实验证明,SwiGLU 在大多数任务上表现最优,成为现代 LLM 的事实标准。
2.4 SwiGLU:胜出的“冠军”
SwiGLU(Swish Gated Linear Unit) 是 GLU 家族中最终脱颖而出的方案。它由 Meta 的 LLaMA 团队率先大规模采用,随后被 Qwen、Mistral、PaLM 等几乎所有主流模型采纳。
SwiGLU 的公式为:
SwiGLU(x) = (x · W_gate) ⊙ Swish(x · W_up)其中 Swish(x) = x · σ(x)(σ 为 Sigmoid 函数)。
让我们拆解一下这个公式的含义:
- 输入投影:输入 x 被分别投影到两条路径——门路(W_gate)和上路(W_up)。在实践中,为了参数效率,这两个投影通常被合并为一个矩阵,再拆分结果。
- 门控生成:门路经过 Swish 激活。Swish 的特点是:在正区域近似线性,在负区域平滑衰减到零附近但不完全为零,且是非单调的(有一个轻微的“凹陷”)。这种平滑、非单调的特性让它能够捕捉更复杂的非线性关系。
- 逐元素乘法:激活后的门控信号与上路的值信号逐元素相乘,实现“选择性通过”。
为什么 SwiGLU 比 GELU 和 ReLU 更好?
- 门控机制:让模型能够动态决定信息流,而不是被固定的函数束缚
- 平滑性:Swish 在负值区域不是直接置零,保留了梯度,避免了“死神经元”
- 非单调性:Swish 的轻微“凹陷”让它在某些输入范围内可以有更强的非线性表达
- 计算效率:Swish 比 GELU 计算更简单,在实践中效果差异不大但工程上更友好
目前,SwiGLU 已经成为 LLM FFN 的“标准配置”,几乎所有新发布的开源大模型都在使用它。
三、FFN 中的维度扩张:为什么是 4 倍?
看过模型配置文件的朋友可能注意过一个参数:intermediate_size(或 ffn_dim),通常是 hidden_size 的 4 倍。比如 LLaMA-7B 的 hidden_size 是 4096,intermediate_size 则是 11008(约为 4096 × 2.69,SwiGLU 下的调整)。
3.1 标准 FFN 的 4 倍规则
在经典 Transformer 中,FFN 的结构是:
输入维度 d → 投影到 4d → 激活函数 → 投影回 d这个“4 倍”不是一个随意选的数字,而是经过大量实验验证的经验最优值。
为什么要扩大中间维度?因为 FFN 需要足够的“容量”来存储知识和完成非线性变换。如果中间维度过小,FFN 会成为一个信息瓶颈,限制模型的学习能力。如果过大,参数量和计算量会急剧膨胀,边际收益递减。
3.2 SwiGLU 下的维度调整
当 FFN 从 GELU 升级到 SwiGLU 时,出现了一个细节问题:SwiGLU 需要三个权重矩阵(输入到门路、输入到值路、合并后到输出),比标准 FFN 多了一个。如果保持同样的 4d 中间维度,参数量会增加 50%,FLOPs 也会相应增长。
为了公平对比,SwiGLU 论文建议将中间维度调整为原来的 2/3 × 4d ≈ 2.67d,以保证参数量和计算量与标准 FFN 大致相当。这就是为什么 LLaMA 的 intermediate_size 是 11008(约为 4096 × 2.69)而不是 16384 的原因。
这提醒我们:看模型参数量的时候,不能只看层数和 hidden_size,FFN 的结构和维度设置同样重要。
四、FFN 与参数量:模型“体重”的主要来源
4.1 FFN 的参数占比
对于一个标准的 Transformer 层:
- Attention 部分:4 个权重矩阵(Q、K、V、O),每个尺寸为 d × d,参数量约为 4d²(不计偏置)
- FFN 部分:2 个权重矩阵(标准 FFN)或 3 个(SwiGLU),尺寸分别为 d × 4d 和 4d × d,参数量约为 8d²(标准 FFN)或约 8d²(SwiGLU 调整后)
因此,单层 FFN 的参数量大约是 Attention 的 2 倍。叠加多层的 Embedding 和最终输出层后,FFN 的总体占比约为 2/3 左右。
4.2 为什么 FFN 需要这么多参数?
这个问题触及了 LLM 设计的核心权衡。Attention 负责“信息路由”——决定哪些 Token 之间要交换信息。它的复杂度是 O(n²)(n 为序列长度),所以 Attention 的参数不宜过多,否则计算量会爆炸。
FFN 则不同。它的计算复杂度与序列长度是线性的(每个 Token 独立处理),因此可以在不显著增加序列级计算负担的前提下,大量堆叠参数来提升模型的“知识容量”。
这就是 Transformer 架构设计的精妙之处:用参数少的 Attention 做“稀疏路由”,用参数多的 FFN 做“密集存储”。两者配合,既保证了长序列的处理效率,又保证了足够的模型容量。
五、从 FFN 到 MoE:当“一个专家”不够用时
5.1 稠密 FFN 的困境
标准 FFN 虽然强大,但有一个根本局限:无论输入是什么,所有参数都会被激活。这意味着,模型规模(总参数量)和每次推理的计算量(激活参数量)是严格绑定的——更大的模型必然带来更慢的推理和更高的显存消耗。
随着模型规模从 7B 增长到 70B 甚至 400B,这种“等比例”的增长变得越来越难以承受。研究者们开始思考:能不能让模型拥有巨大的总参数量,但每次推理时只激活其中一小部分?
5.2 MoE 的核心思想:专家分工,按需激活
MoE(Mixture of Experts,混合专家) 正是对这一问题的回应。MoE 层的结构如下:
- 多个专家 FFN:MoE 层不再只有一个 FFN,而是包含 N 个独立的 FFN(称为“专家”),每个专家都有自己的完整参数。
- 路由器(Router/Gating Network) :一个轻量级的网络,负责为每个输入 Token 选择最合适的专家。
- 稀疏激活:对于每个 Token,路由器只选择 Top-K 个专家(通常 K=1 或 2),只有被选中的专家被激活参与计算。
这样一来,模型的总参数量 = 所有专家的参数之和,而每次推理的激活参数量 ≈ 被激活专家数 / 总专家数 × 总参数。
举个例子:一个 MoE 模型有 64 个专家,每次激活 Top-2,那么它的总参数量是稠密模型的 64 倍,但每次推理的计算量只是稠密模型的 2 倍。Voyage AI 的实践表明,使用 MoE 架构可以在几乎相同的检索精度下,将激活参数量减少 75%。
MoE 的直觉是:将“知识容量”与“计算成本”解耦。模型可以像一座巨型图书馆一样存储海量知识,但每次查资料时只需要走进其中一个书架。
5.3 经典 MoE 的两大问题
MoE 看似完美,但在实践中暴露了两个根本问题:
问题一:知识混杂(Knowledge Hybridity) 。经典 MoE 通常只有 8 到 16 个专家。专家数量少意味着每个专家必须处理极其多样化的输入——一个专家可能同时要处理“数学推理”和“情感分析”的 Token。结果就是:专家被迫学习混合在一起的不同领域知识,难以真正“专精”某一方向。
问题二:知识冗余(Knowledge Redundancy) 。不同专家都需要掌握一些共有的基础能力,比如“基本语法规则”“常见词汇含义”等。结果是,这些基础能力被多个专家重复存储,造成了参数浪费。
5.4 DeepSeekMoE:细粒度专家与共享专家
DeepSeek 团队针对上述问题提出了两大创新策略,成为 MoE 架构演进中的里程碑式工作:
策略一:细粒度专家分割(Fine-Grained Expert Segmentation)
DeepSeekMoE 将每个专家按照 FFN 的中间隐藏维度进一步拆分为多个更小的专家。例如,原来的 16 个专家,每个拆分为 4 个,得到 64 个细粒度专家,同时激活数量也相应增加(如从 2 个增至 8 个)。
好处是什么?专家数量大幅增加,每个专家可以更加“专精”,知识混杂问题得到显著缓解。效果非常惊艳:DeepSeekMoE 的 16B 模型仅用 40% 的计算量就达到了 DeepSeek 7B 和 LLaMA2 7B 的性能水平。
策略二:共享专家隔离(Shared Expert Isolation)
DeepSeekMoE 在路由专家之外,额外设置了共享专家——这些专家的输出始终被保留,不经过路由选择。共享专家负责存储所有 Token 都需要的“通用知识”,而路由专家则可以专注于各自的“专业领域”。
这种方法完美解决了知识冗余问题:通用能力由共享专家统一提供,各路由专家不再需要“重复造轮子”,参数效率大幅提升。
此外,DeepSeekMoE 还采用了归一化 Sigmoid 门控(Normalized Sigmoid Gating) 来替代传统的 Softmax 门控,进一步提升了训练稳定性和专家利用率。
从工程效果来看,DeepSeek-V3 展示了 MoE 架构的极致潜力:671B 总参数,推理时仅激活 37B,却能实现 GPT-4 级别的性能。到 2025 年底,MoE 架构已经占据了超过 60% 的开源 AI 模型发布量。目前,所有披露架构的 Top-10 前沿模型全部都是 MoE。
六、FFN 与训练稳定性:Pre-Norm 的必要性
在上一篇文章中,我们提到了 Pre-Norm 是现代 LLM 的标配——归一化放在 Attention 和 FFN 之前,而非原始 Transformer 的 Post-Norm(放在之后)。
Pre-Norm 对 FFN 层同样重要。随着层数增加到几十甚至上百层,Post-Norm 容易导致梯度在反向传播中逐渐消失,使得深层网络的训练极不稳定。而 Pre-Norm 通过在每个子层(Attention 和 FFN)之前做归一化,让梯度传播更加平滑,从而支持更深的网络结构。
这一点在 FFN 层尤为关键,因为 FFN 的参数量最大,对梯度不稳定也更加敏感。采用 Pre-Norm 后,即使是 70B、80 层的模型也能稳定训练收敛。
七、最新研究前沿:FFN 架构的“进化树”
除了 MoE 之外,FFN 的研究在过去一年中涌现出了多个令人兴奋的新方向。
7.1 MoC:利用 SwiGLU 原生稀疏性
Mixture-of-Channels(MoC)是一篇 2025 年的工作,它提出了一个非常聪明的想法:利用 SwiGLU 自带的门控信号来直接实现 FFN 的稀疏化。
研究者首先对 LLM 进行了详细的内存分析,发现在引入 FlashAttention 后,FFN 的激活值已成为显存的主要瓶颈。MoC 的做法是:在每个 Token 的 FFN 计算中,只激活由 SwiGLU 门控信号决定的 Top-K 最相关通道,从而大幅减少激活内存的占用。这种方法不需要额外的路由网络,直接“就地取材”,在预训练和推理阶段都能显著提升效率。
7.2 从“专家”到“轨迹”:MoE 可解释性的新发现
一篇 2026 年的论文提出了一个颠覆性的观点:MoE 中真正有意义的最小单元不是单个专家,而是专家在不同层之间形成的“轨迹” 。
研究发现,虽然单个专家是“多义的”——同一个专家可能处理多个完全不相关的概念——但一个 Token 在多个层之间依次访问的专家序列,却表现出了高度一致的语义模式。同一 Token 在不同上下文中(例如冒号“:”在不同用法下)会沿着截然不同的“专家轨迹”前进,而相同语义功能的 Token 会聚合成清晰的轨迹簇。
这项研究为 MoE 的可解释性提供了全新的视角:不要问“这个专家是做什么的”,而要问“这条专家路径通向哪里”。
7.3 FIRM-MoE:专家细粒度卸载
随着 MoE 模型规模继续膨胀(数百亿到数千亿参数),单个 GPU 甚至单个节点的显存都不够用。FIRM-MoE(Fine-Grained Expert Decomposition for Resource-Adaptive MoE Inference)提出了一套细粒度的专家卸载框架,允许模型根据硬件资源动态决定哪些专家放在 GPU 显存中、哪些放在 CPU 内存中,在保持精度的同时灵活适应不同的部署环境。
八、工程实践:如何配置 FFN?
8.1 场景驱动的选择
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 7B 以下小模型 | 标准 FFN + SwiGLU | MoE 的路由开销在小模型上不划算 |
| 中大规模(13B-70B) | MoE + SwiGLU(激活比 1/10) | 用稀疏激活换取更大总参数量 |
| 多语言/多领域 | DeepSeekMoE 风格 | 共享专家 + 细粒度专家,适配多样知识 |
| 极致推理效率 | MoC(Mixture-of-Channels) | 利用 SwiGLU 原生稀疏性,无需额外路由 |
| 资源受限部署 | FIRM-MoE 卸载策略 | 灵活调配 GPU/CPU 内存 |
8.2 SwiGLU 的实现
在 PyTorch 中实现 SwiGLU FFN 非常简单:
import torch.nn as nn
import torch.nn.functional as F
class SwiGLU_FFN(nn.Module):
def __init__(self, d_model, d_ffn):
super().__init__()
# 标准 SwiGLU:两个投影矩阵
self.gate_proj = nn.Linear(d_model, d_ffn, bias=False)
self.up_proj = nn.Linear(d_model, d_ffn, bias=False)
self.down_proj = nn.Linear(d_ffn, d_model, bias=False)
def forward(self, x):
# SiLU = Swish
gate = F.silu(self.gate_proj(x))
up = self.up_proj(x)
return self.down_proj(gate * up)如果追求极致效率,还可以将 gate_proj 和 up_proj 合并为一个矩阵,减少一次 Kernel 启动开销。
九、总结与展望
9.1 FFN 的“进化路线图”
| 阶段 | 代表技术 | 核心贡献 | 代表模型 |
|---|---|---|---|
| 1.0 基础时代 | ReLU FFN | 引入非线性 | 原始 Transformer |
| 2.0 平滑时代 | GELU | 缓解 Dead ReLU | BERT, GPT-2 |
| 3.0 门控时代 | SwiGLU | 动态信息路由 | LLaMA, Qwen, Mistral |
| 4.0 稀疏时代 | MoE(Top-K 路由) | 容量与计算解耦 | Mixtral, GPT-4 |
| 5.0 精细时代 | DeepSeekMoE(共享+细粒度) | 解决知识混杂与冗余 | DeepSeek-V2/V3 |
| 6.0 原生稀疏时代 | MoC(Mixture-of-Channels) | 利用 SwiGLU 自带稀疏性 | 前沿研究 |
9.2 FFN 在整个 LLM 架构中的定位
回顾我们整个系列的数据流:
- Tokenizer → Token ID 序列
- Embedding → 高维语义向量
- RoPE → 注入相对位置信息
- Attention(GQA) → Token 间信息交互
- FFN(SwiGLU / MoE) → 知识存储与非线性变换
- 回到步骤 4,循环 N 层
- 输出层 → 预测下一个 Token
FFN 在其中的角色是 “知识的加工厂和存储器” 。Attention 负责“找谁交流”,FFN 负责“交流后怎么消化和记忆”。
9.3 未来趋势
- 更细粒度的 MoE:专家数量持续增加,激活机制更加智能,DeepSeekMoE 的成功证明了这一方向的巨大潜力
- 原生稀疏 FFN:不依赖额外路由,直接利用激活函数自身的稀疏特性,如 MoC 所示
- FFN 与 Attention 的深度融合:打破传统的“Attention → FFN”固定顺序,探索更灵活的模块编排方式
- FFN 的可解释性:从“专家”到“轨迹”的视角转变,正在打开 MoE 模型内部运作的“黑箱”
- 绿色 AI:FFN 占据 2/3 的参数和大量计算,优化 FFN 效率直接关系到降低大模型的碳排放
作者
884705373@qq.com
相关文章