写在前面
在前面的六篇文章中,我们完整拆解了Transformer的静态架构——从Tokenizer到Embedding,从FFN到Attention,从残差连接到归一化。但至此,我们解答的还只是“模型长什么样”的问题。
从这篇文章开始,我们要把目光从“静态结构”转向“动态运行”——当模型真正开始逐字生成文本时,底层到底发生了什么?为什么一个明明只有7B参数的模型,跑起来却需要几十GB的显存?为什么同一个句子里的词,模型要反复计算那么多次?
这些问题的答案,指向一个贯穿LLM推理始终的关键机制——KV Cache。而真正让KV Cache的内存管理从“粗放”走向“精细”的革命性技术,叫做 PagedAttention。
如果说KV Cache是LLM推理的“发动机”,那么PagedAttention就是为这台发动机装上的“高效燃油系统”。今天这篇文章,我们将深入拆解这两个紧密相关的技术,讲清楚它们为什么如此重要,以及它们如何共同推动了整个LLM服务领域的效率革命。
一、KV Cache:LLM推理的“发动机”
1.1 自回归生成的“效率陷阱”
要理解KV Cache的价值,首先要理解它要解决的根本问题。
LLM生成回答的过程,叫做自回归生成——一个字一个字地往外蹦。每生成一个新Token,模型都要把它放到整个序列的末尾,重新对整个序列做一遍Attention计算。用数据流来直观地看:生成第1个 Token,模型处理1个位置;生成第2个 Token,模型处理2个位置;生成第 n 个 Token,模型处理 n 个位置。
这意味着,输入序列中的每一个早期Token,都会被反复处理很多次。一个位于Prompt开头的词,可能会被计算几百甚至上千次——而且每一次的计算结果,和上一次相比没有任何变化。
这种重复计算带来的开销是巨大的:总计算量以序列长度平方级别增长(O(n²)),序列越长,计算代价越沉重。
1.2 Attention中最具启发的观察
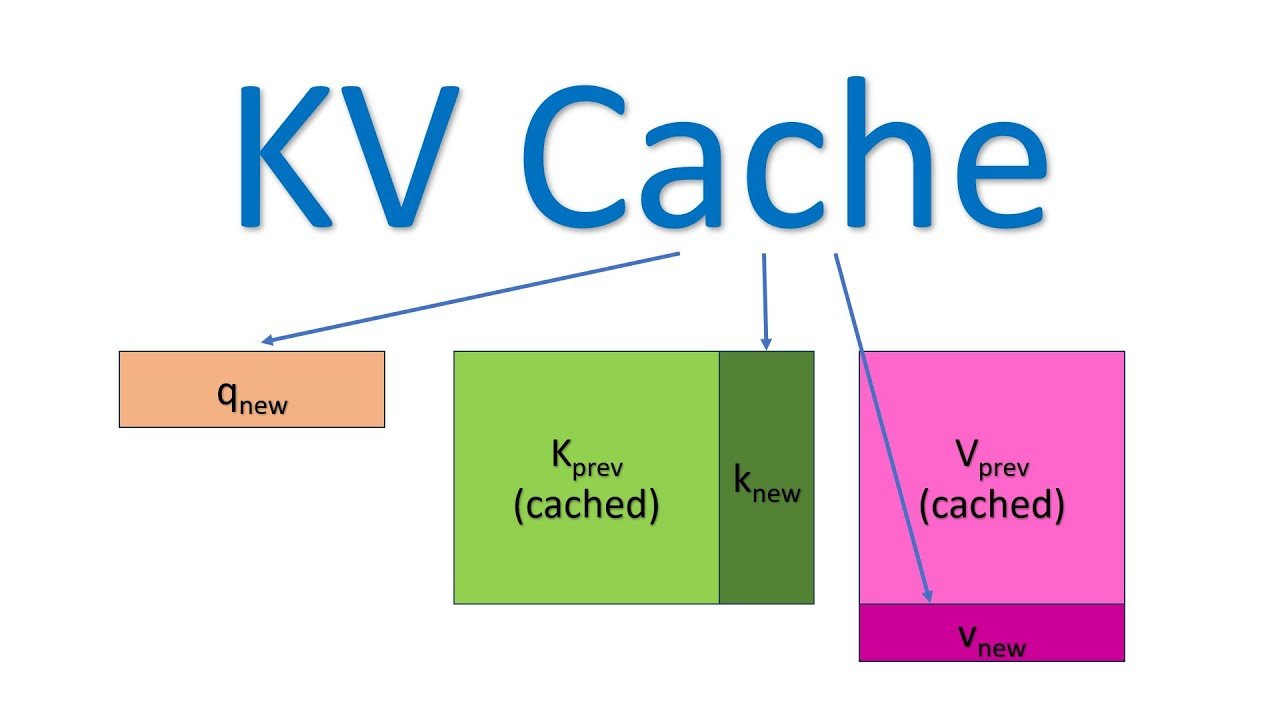
在Transformer的Self-Attention中,每个Token被用来计算三个向量:Query(Q)、Key(K)和Value(V)。
一个关键的观察是:对于一个已经生成出来的“历史Token”而言,它的Key向量和Value向量,在后续的生成过程中不会再发生任何变化。
为什么呢?因为Key和Value只依赖于这个Token本身的Embedding——而一个历史Token的Embedding是固定的。无论未来再生成多少个新词,它的K和V都不会变。唯一会随着序列推进而不断更新的是新Token的Query,但它不需要和K、V一起“旧事重提”。
1.3 缓存决定性的思想:算完就存起来,别扔
所以,KV Cache的思想是颠覆性的:不要把那些辛辛苦苦算出来的K和V扔掉了!把它们缓存起来!
在Prefill阶段,模型接收用户输入Prompt的所有Token,预先计算并缓存它们的K和V向量。随后进入解码阶段,每生成一个新Token,模型只需要为新Token计算一份新的K和V,然后用它的Q去Cache里取所有历史K计算分数。整个过程,旧Token的Key/Value完全不需要从头计算。
效果是显著的:计算复杂度直接从O(n²)降到了O(n) 。每生成一个新Token,只需要常数时间的运算,实际推理速度可能提升3到5倍,顺序越长效益越明显。在128K长序列的极端情况下,甚至可能快10到20倍。
1.4 KV Cache的计算代价有多大?
但天下没有免费的午餐。KV Cache虽然大幅降低了计算量,但它把代价转移到了显存占用上。
K和V向量的缓存驻留在GPU显存(HBM)中。KV Cache的显存消耗遵循以下公式:
- 对于每个Token,每层、每个头,都需要存储一个 K 向量和一个 V 向量。
- 批处理大小(Batch Size)再乘上同时处理的请求数。
根据实际测量,当上下文超过8000 Token时,KV Cache的显存占用就会超过模型权重。到1M上下文时,KV Cache可能会吃掉超过95%的总显存。更直观的体感是,处理百万级上下文的推理,其KV Cache可能占用数百GB的显存。因此,KV Cache的这种无序扩张,正在成为大型语言模型推理部署的核心瓶颈。
1.5 传统内存分配的三宗罪
在PagedAttention出现之前,推理框架(比如最原始的Hugging Face Transformers实现)对待KV Cache的方式非常粗放:
- 预留式分配:系统会为每个推理请求,在显存里预先划定一块巨大的、连续的物理空间,其大小直接等于“最大可能生成的序列长度”。绝大部分预留好的显存其实什么都没有写,但系统不敢复用,造成了残酷的内部碎片。
- 物理连续性:传统Attention Kernel要求KV Cache必须在显存中连成一片。在处理大量并发的、长度各异的请求时(有的只聊两句,有的要长篇大论),这种分配方式催生了更加恶劣的外部碎片。小块无效内存夹在不同长度的活跃Cache之间,成了无人能用的“孤岛”。
- 静态独占:每个请求独享一整块预留区域,直到生成结束才整体释放,无法动态伸缩或共享。
在实践中,这种“粗放式经营”的恶果是显存中充斥着大量的无效碎片。有分析指出,传统内存管理方式下,高达80%的预留显存在大部分时候都是空置的。模型显存虽大,可并发处理多个请求的能力(吞吐量)却被严重束缚了。
二、PagedAttention:解开KV Cache的“内存死结”
2.1 革命性的灵感:经典的虚拟内存分页
面对满目疮痍的显存碎片,来自UC Berkeley的vLLM团队没有接着在Attention公式本身上“打补丁”,而是做出一个大胆的跨界类比:显存碎片化?这不是操作系统的虚拟内存管理早就解决了的问题吗?
操作系统早就抛弃了为每个进程预留大块连续物理内存的做法。取而代之的是分页机制:把整个内存空间切分成一个个固定大小的小块(Page),再用一张全局的“页表”把“进程视角下连续的逻辑地址”,灵活地映射到物理内存中任意不连续的空闲页上。
他们在2023年的SOSP会议上,将这个已经过半个世纪检验的工程哲学,完美迁移到了KV Cache的管理上,命名其为——PagedAttention。
2.2 区块化的KV Cache:它是如何运作的?
PagedAttention改变了KV Cache的基本存储单位。它不再按“整个序列”分配内存,而是强制将每个序列的KV Cache,在底层切分成一个个固定大小的 Block。常见的块大小是 16 或 32 个Token作为一个Block。
每个序列内部维护一个 Block Table(块表)。它将Token的“逻辑位置”(例如,Token 0-15在逻辑块#0)映射到这个逻辑块在当前时刻所在的真实“物理块”编号。多个请求内部使用各自不同的块表做映射,它们的KV cache实际上可能散落在显存的各个角落。但从单个请求视角看,它们依然形成了一个逻辑上连续的序列。因此,Block Table就相当于操作系统的页表。
2.3 内存效率的革命性提升
这种颗粒度稍粗但极其灵活的管理,带来了至少三个维度的显著收益。
首先,内部碎片几乎彻底消失:系统只为已经生成出来的Token分配下一块Block,而且每块都不大。一个请求当前剩几个Token没装满,就浪费几个位置,造成的内存浪费平均远低于传统预留方案的20-40%。
其次,外部碎片彻底消除:因为是动态映射,不要求物理块连续,所以“外部碎片”这个概念在PagedAttention体系下从根本上消失了。系统可以高效支配每一寸空闲的GPU内存,利用率空前提高。
最后,按需动态伸缩:随着序列不断生成新内容,Block Table动态追加映射新的物理块。当请求完成后,块被整体回收到一个全局的空闲块池子里供新请求使用。
2.4 终极秘诀:零冗余的Copy-on-Write共享
在真实LLM服务场景中(如RAG或者并行采样),一个团队往往会针对同一段很长的系统提示词(System Prompt),发送多个不同的用户问题。如果不采用共享机制,系统必须为每个并发的请求团,单独分配并计算同一份系统提示词的KV Cache。
而PagedAttention通过在Block Table层面实现“写时复制” 语义,优雅地解决了此问题。当从同一个System Prompt派生多个新请求时,系统只需要为这些请求创建新的逻辑块表,而表里大部分条目映射到了一份来自源请求的相同物理块上。只有当新请求自身后续生成的独特内容超出了这些共享块时,才会为它触发新的物理块分配。
由于无需额外计算或重复存储,共享组所需的显存,与只有一个请求的情况几乎相同。vLLM的评估显示,这项特性最高可将内存浪费进一步降低约55%,并带来至多2.2倍的吞吐量提升。
2.5 激进加速背后的工程复杂性
当然,这种灵活性的代价是底层的工程复杂度成倍上升。Block Table带来了额外的硬件跳转指令,非连续内存访存也对GPU并行性构成考验。
为此,vLLM必须配套开发一个全新的、高度优化的 CUDA Attention Kernel ,以高效处理这种“散落在各处”、靠Block Table索引的KV Cache。该核函数使用了精巧的策略(比如线程粗化、向量化加载、Warp级并行归约),大幅压低了地址映射和调度造成的开销。此外,vLLM还设计了 v2分区式核函数,专门用于应付上下文极长(如128K Token)的场景,避免单核函数局部显存溢出导致的崩溃。
2.6 从论文到落地:PagedAttention开源生态与现实影响
PagedAttention从根本上改变了大模型落地服务的成本曲线。
在基准测试中,搭载PagedAttention的vLLM推理框架展现出了惊人的能效优势。相比未优化的Hugging Face(HF)以及专门设计的Text Generation Inference(TGI):vLLM的吞吐量最高可达HF的24倍,TGI的3.5倍。
这种颠覆性的效率提升,使得vLLM和背后的PagedAttention迅速成为了整个LLM推理领域的实际标准。近两年,它已从一项单纯的学术原型,成长为业界包括Anyscale、Modal、Baseten、AWS、Google Cloud等众多LLM推理服务的默认基石或集成方案。毫不夸张地说,PagedAttention的CMO(首席内存官)级别设计,为2024-2026年间大模型应用的平民化提供了最主要的工程推力之一。
三、前端探索:KV Cache正在发生什么?
聊完了作为核心引擎的KV Cache和奠定内存管理基石的PagedAttention,我们现在将视野投向前沿。面对百万Token上下文时代的到来,全行业都在沿着不同的技术路径,试图驯服KV Cache这头仍在疯狂成长的“显存巨兽”。
3.1 极限量化:谷歌TurboQuant的破壁时刻(2026)
量化是最古老也一直在用的疗法。但过去,量化精度降到一定程度(比如4-bit以下)总要面临一个命门——精度损失导致模型输出变差。
2026年3月,谷歌在ICLR推出的 TurboQuant 却震动了整个行业。它声称可以把高精度(FP16)的KV Cache,惊人地无损压缩至3.5 bits——压缩率直逼6倍,并实现8倍的推理加速,引发了美光、西部数据等内存巨头的股价震动。
TurboQuant到底做了什么?它组合了一套极其聪明的变换量化法:
- PolarQuant(极坐标量化):放弃传统的XYZ坐标,将高维向量先投影成“角度”,由于角度分布很集中,描述它只需极低的码率。
- QJL(量化JL变换):再把投影产生的微小偏差用+1/-1的符号编码作为残差校正,几乎零额外开销地消除了误差。
随着技术成熟,它可能从根本上改变GPU硬件需求,让单卡带动数百万甚至无限的上下文不再遥不可及。业内预测,若该技术未来彻底成熟,当前用于AI服务的数据中心GPU需求或减少50%以上。
3.2 超长上下文的缓存驱逐难题:2026的多元解法
当上下文窗口突破百万Token,单纯靠存储已无法满足需要。
- LookaheadKV:一种预测-验证式驱逐法。它通过异步“偷窥”未来可能的状态,来决定现在哪些KV是“万万不能扔的”(长尾依赖),在LongBench上实现了仅需6%的缓存,依然逼近99%完整缓存的性能。
- TTKV(Temporal-Tiered KV Cache):提出了“时间分层”架构。刚生成的KV速度快且频繁访问,放快速存储;历史古早的KV通过一种层间复用索引访问,放慢速存储。在128K任务上跨级流量减少了5.94倍。
- KeyDiff:一种完全不依赖训练、计算也极轻的驱逐方法。它在长上下文推理中,可基于Key向量之间的纯几何相似度,快速识别并扔掉“语义上最无关紧要的KV对”,特别适合资源受限小型设备。
3.3 跨请求复用:从零计算到”存了一次,受益终身”
传统的KV缓存是“一次性的”:同一个系统提示词(System Prompt),虽被成千上万次调用,每次却仍然要重复从零构建。
LMCache(2025) 彻底改变了这个范式。通过在GPU、CPU内存甚至本地NVMe磁盘上建立多层级、持久化的KV Cache存储,LMCache使得相同或相似文本的缓存,能够在完全无关的请求之间智能复用。实测数据显示,在聊天机器人、RAG及多轮对话场景下,使用LMCache能够将首Token延迟(TTFT)大幅缩减,获得3至10倍的速度提升而不损失任何吞吐量。
3.4 Spotlight Attention:给长上下文画一条“捷径”(2025)
如果上下文长达512K甚至百万Token,“查找相似Key”这个动作,也可能变成拖垮推理的主犯。
Spotlight Attention(2025) 为此提供了一个思路:利用新型的非线性哈希函数,为每一个Key和Query预先计算出一个超高效率的检索索引。它通过C++/CUDA协同设计的极致kernel优化,面对512K的KV海洋时,每次检索时间不到100微秒,端到端吞吐量是原生解码的3倍以上。
3.5 分层语义压缩:SentenceKV(2025)
许多驱逐策略忽略了KV向量内部的深层语义规律。当面对一本书篇幅的上下文时,大量Token其实在传递相似的信息。
SentenceKV另辟蹊径,将KV压缩放到了句子语义相似度的层级。它在Prefill阶段就利用编码器提取句子的高维语义向量,解码时,直接对比生成中查询的语义向量,提前精准预测“需要哪个句子的KV块”,把整个庞大的上下文变成一句话级别的“内容地图”快速索引,大幅降低无效显存冗余。
四、动态演进:从MHA/MLA到全覆盖优化的架构革新
与此同时,在架构层面,对KV Cache的精简也在持续进化,与系统管理形成软硬一体的配合。
- DeepSeek MLA再审视:我们曾在Attention一讲提到,MLA基于低秩分解将KV的显存压缩比推到极致。最新研究表明,一个从GQA迁移至MLA架构的LLaMA模型,其KV Cache直接缩减了92.19%~93%,模型质量仅微跌不到1%,推理速度却获得10.6倍的加速。
- MLA迁移工具:2025年ACL的工作已实现零成本转换——无需完整训模型,仅用一小部分数据微调(0.6%~1%),就可以将任何成熟的Transformer模型无缝迁移到极低KV占用的MLA架构上,极大降低了该技术的准入门槛。
- MoE-nD(2026):该框架在整个KV缓存的多维度(Token驱逐、量化、降维、层共享)上,通过混合专家(MoE)模型,对每一层Transformer进行动态路由,实现最“个性化”的KV压缩。在几乎不发生质量损耗的前提下,将庞大的1.9GB缓存狂压至136MB(压缩率高达14倍)。
- GRACE(2026):将KV Cache的通道剪枝化为图谱优化问题。每个通道为“结点”,通道间关系为“边权重”,通过最小化注意力矩阵重构误差来识别最优最小子图,在省下60%缓存空间的同时,近乎零性能退化。
五、总结与展望:深度融合与软硬一体的未来
5.1 演进路线总结
| 维度 | 早期方案 | 当前主流 | 未来方向 |
|---|---|---|---|
| 计算效率 | 重复计算O(n²) | KV Cache (O(n)) | 稀疏注意力、CPU-GPU融合 |
| 显存管理 | 静态连续分配 | PagedAttention、vLLM | 语义分层、共享池化 |
| 架构压缩 | MHA(倍乘开销) | GQA/MQA、MLA (DeepSeek) | 零训练迁移、MoE路由压缩 |
| 序列扩展 | 预留、丢弃 | Lookahead/TTKV | 语义预测、哈希捷径 |
| 精度与位宽 | FP16/BF16 | KV FP8压缩 | TurboQuant 3.5-bit 无损 |
| 多请求复用 | 物理隔离,0复用 | Prefix Caching | LMCache跨请求全局复用 |
5.2 融合智能与硬件的未来
我们已经看到KV Cache在系统、算法、架构三个维度上的全面优化。而未来,这三个维度的边界正在加速模糊——迈向“软硬一体、深度协同”的时代:
- CPU-GPU的深度融合计算框架(如 HybridGen)不再把KV Cache当作GPU专有财产,通过CXL等技术将其扩展至CPU、NVMe、SSD等多个层级的存储池,实现更灵活、大容量的混合推理。
- 基于存内计算(PIM)的直接计算架构,有可能从硅基层面彻底卸掉“内存墙”这一物理天花板。
- 多上下文(SamKV)场景下的极致KV复用算法,在超大规模长文档汇总场景,未来可能仅以15%的缓存开销实现同等功效。
这一切都指向同一个终极目标:让大模型在真正的生产环境中,以最低的成本、处理最复杂的任务、并覆盖最广泛的人群。
作者
884705373@qq.com
相关文章