在
从“重复劳动”到“智能记忆”:KV Cache与PagedAttention深度解析
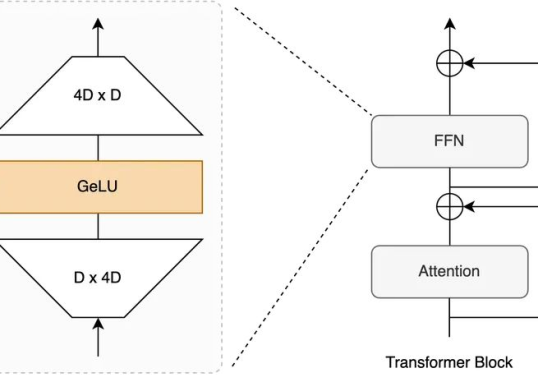
写在前面 在前面的六篇文章中,我们完整拆解了Transformer的静态架构——从Tokenizer...
读出全部tech life love
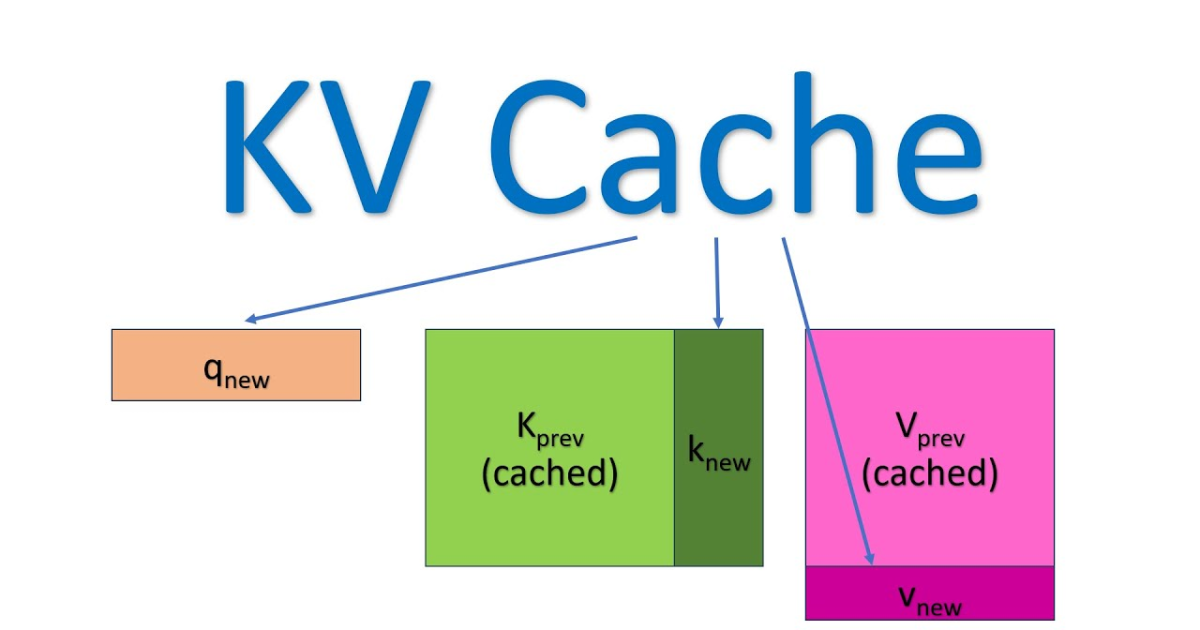
写在前面 在前面的六篇文章中,我们完整拆解了Transformer的静态架构——从Tokenizer...
读出全部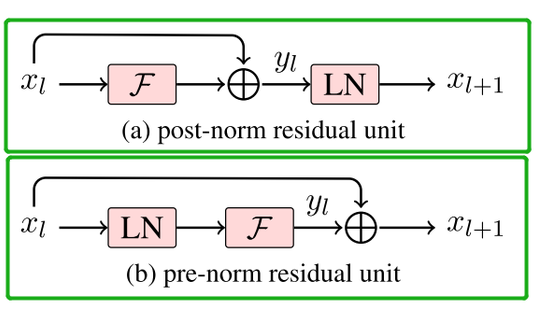
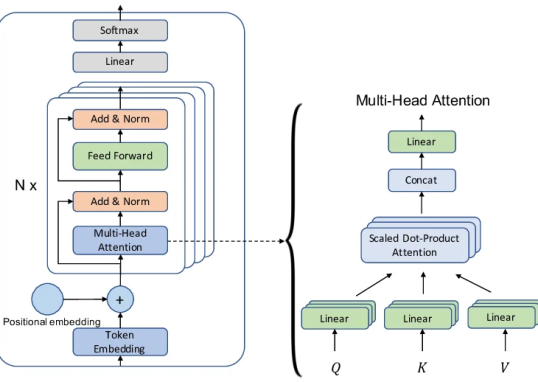

从全量微调的昂贵代价,到 LoRA 的轻量适配,再到 QLoRA 在 48GB 显存上微调 65B ...
读出全部