tech life love
Hello World! 这是用来记录自己学习工作的博客站,也会在这里更新我的日常生活(作为我的树洞)。
为什么开发者需要Claude Code?AI编码助手的崛起 随着AI技术在开发工具中的深度集成,Cl...
什么是Agent流程编排?为何它正在重塑AI应用架构 在上一节中,我们探讨了智能代理(Agent)的...
引言:为什么Yarn需要上下文扩展? 在上一节中,我们探讨了Yarn插件系统的整体演化路径,而要真正...
引言:为什么大模型微调需要QLoRA? 在深入LoRA微调机制之前,我们必须直面一个现实:当今主流大...
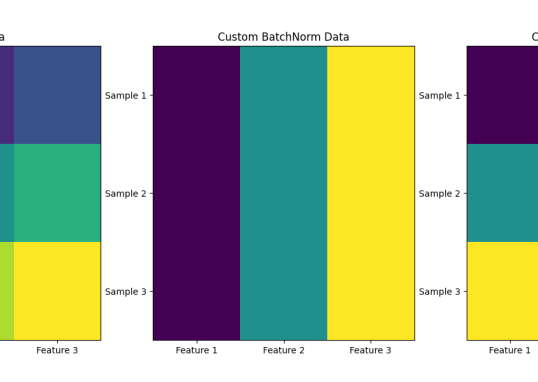
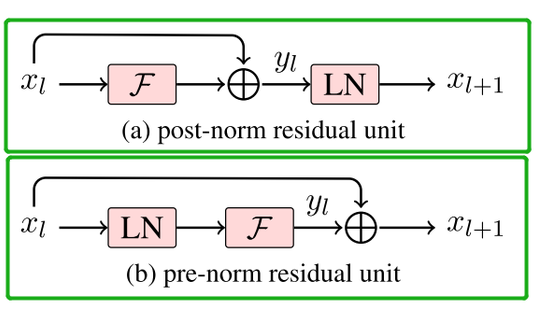
可以说,如果没有残差连接和 Layer Normalization(层归一化)这样一刚一柔的黄金组合...
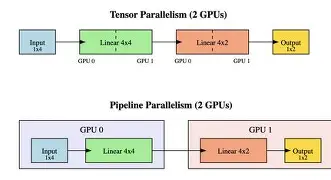
写在前面 在上一篇文章中,我们讨论了如何用数据并行、张量并行和流水线并行,把一个大模型“拆开”放到成...
写在前面 目前为止的文章都在聊一件事:单个模型内部的“微观世界” ——Embedding怎么工作、A...
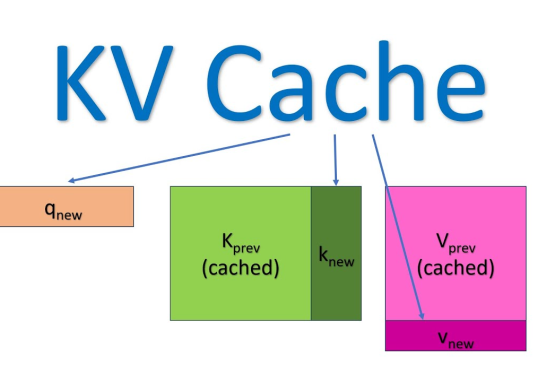
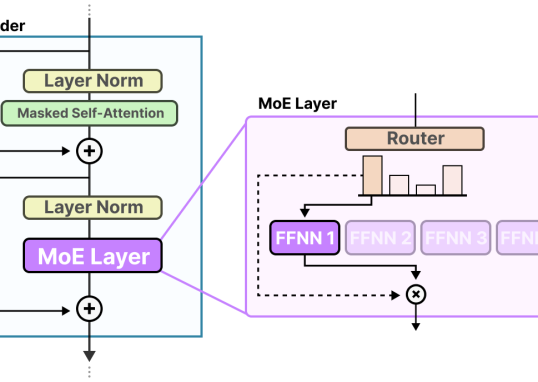
如果说我们之前拆解的所有Transformer组件——从FFN到Attention——都是为了让单个...
写在前面 在前面的六篇文章中,我们完整拆解了Transformer的静态架构——从Tokenizer...
写在前面 在前几篇文章中,我们像拆解一个精密的机械表一样,一步步解剖了 LLM 的各个核心组件:从 ...