可以说,如果没有残差连接和 Layer Normalization(层归一化)这样一刚一柔的黄金组合,动辄上百层的大语言模型(LLM)恐怕早已在训练过程中变成了 NaN 的温床。之前我们在 Pre-Norm/Post-Norm 那篇文章里,聊了它们和残差结构联手护航梯度流动的故事。而今天,我们要把放大镜对焦到 Layer Normalization (LN) 本身,深入探索一个由精细的“全活”手艺—— LayerNorm ,并揭秘它的“后浪”—— RMSNorm——是如何用一招极致的减法,统治了如今的大模型世界的。
一、LN 以前:BatchNorm 的黄金时代与“水土不服”
在 Transformer 出现之前,Batch Normalization (BN) 才是深度学习里风光无限的“标配” 。它在每个 mini-batch 内,对每个特征通道分别求均值和方差来归一化,再搭配可学习的缩放与平移参数,大大加快了训练、缓解了梯度问题。
但 BN 有个软肋:太依赖批大小和序列长度。对 CNN,mini-batch 够大时,算出来的统计量很稳;可一旦 batch size 小,统计量就不准了。更要命的是,当它遇上为“可变序列”而生的 Transformer 时,问题更严重:语言序列长短不一,且注意力层可能只关注到特定位置的 token——这些都对 BN 的批次统计提出了巨大挑战,使得其无法直接应用于 Transformer 架构。而且,Transformer 推理时往往是一个一个 token 地生成,BN 训练与推理统计量不一致的顽疾,也让它在 LLM 领域彻底“水土不服”。
于是,需要一种计算不依赖 batch、能稳定处理变长序列的归一化方法——LayerNorm 应运而生,从 BN 手中接过了接力棒。
二、LayerNorm 简介:不沟通,只耕耘自己的一亩三分地
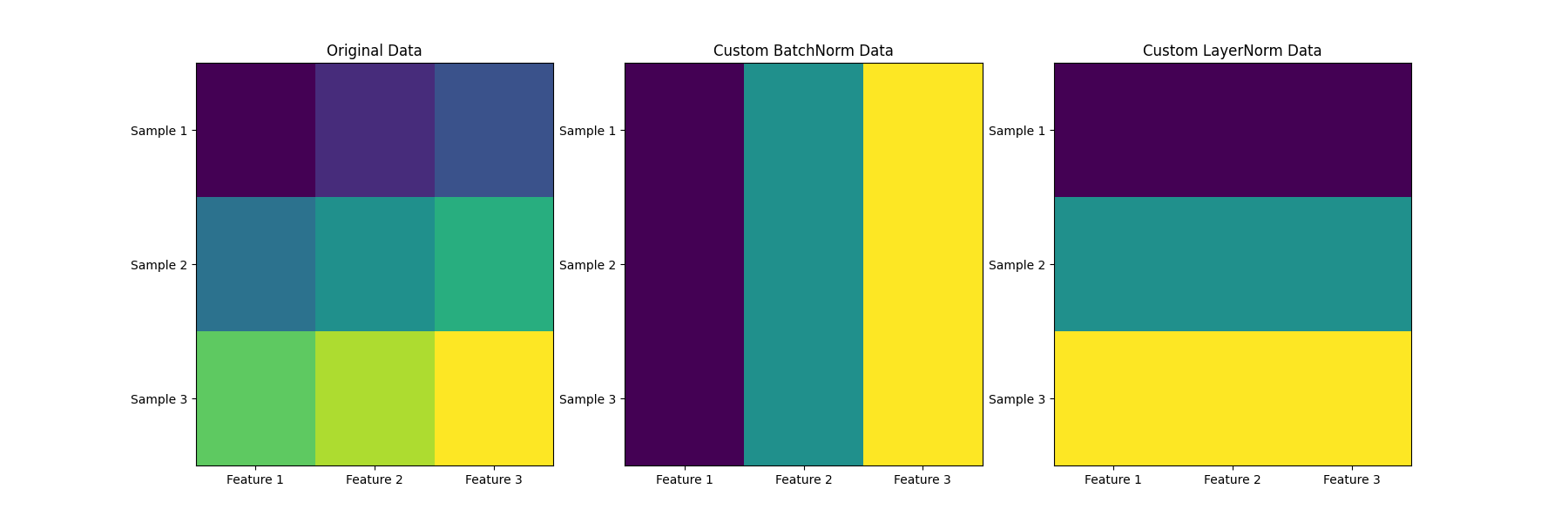
LayerNorm 的思路很“独”:它不像 BN 那样跨越批次进行统计,而是每次只聚焦于一个训练样本,沿着“特征”维度去计算均值和方差,并对每个样本的所有特征进行归一化。这不仅让训练和推理行为做到完全一致,还让它在 RNN 和早期的 Transformer 等序列模型中表现卓越,有效缓解了梯度问题,增强了模型稳定性。
更重要的是,它在平衡模型的“信号强度”方面扮演了关键角色。以均方误差(MSE)为例,若不进行归一化,不同量级的输入值会造成梯度幅值的剧烈波动;而 LayerNorm 通过将数据标准差控制在一个合理的区间内,能实现更平稳的参数优化过程。此外,由于 LayerNorm 将数据范围限制在一个可控的区间,它还为后续采用 8-bit 或 16-bit 浮点数等低精度计算提供了更坚实的基础。
这就是 LayerNorm 的经典公式:
[
y = \frac{x – \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta
]
其中,$\mu$ 是样本特征的均值,$\sigma^2$ 是方差,$\epsilon$ 是为了数值稳定的小常数,$\gamma$ 和 $\beta$ 则是让模型保留数据表达空间的可学习缩放与偏移参数。整个归一化过程可以理解为:先减去均值 $\mu$(中心化),将数据平移到以 0 为中心的位置;再除以标准差 $\sqrt{\sigma^2 + \epsilon}$(缩放),将数据的尺度压缩到标准范围内;最后通过 $\gamma$ 和 $\beta$ 进行仿射变换,保留必要的表达空间。
三、LayerNorm 的几何哲学:为何去掉均值是关键?
2025 年的一项研究,从更深的几何视角揭示了 LayerNorm 的工作方式,让它变得更直观且富有画面感。
可以想象一个高维空间,其中的单位向量 $\boldsymbol{1} = [1, 1, …, 1]^T$ 指向一个“平均方向”。研究指出,LayerNorm 的整个标准化过程,可以清晰地分解为三步:
- 移除“背景噪音”:将输入向量沿着单位向量 $\boldsymbol{1}$ 方向的分量移除。
- 统一尺度:将剩下的向量归一化到单位长度。
- 适配模型空间:在归一化后的向量上乘以 $\sqrt{d}$,其中 $d$ 为向量维度,将其尺度调整到适合模型后续处理的范围。
这项研究的突破性不仅在于其清晰的几何解释,更在于一个关键性的推论:运用 LayerNorm 训练好的 LLM,在推理时的所有隐藏层表示,最终都会“不约而同”地趋向于与 $\boldsymbol{1}$ 向量正交的方向。这意味着,训练完成后模型所有表示的平均值都天然接近 0。
这意味着,LayerNorm 里那个“减去均值”的步骤,最终在训练完成的模型里几乎成了一种天然的冗余操作。这个发现,无疑为 RMSNorm 为何好用,提供了一个关键的“作案动机”。
四、RMSNorm 简介:如何用一次减法,赢得整个 AI 界的心
既然最终模型会让“减去均值”变成多余的步骤,那不如一开始就把它去掉——这就是 RMSNorm(Root Mean Square Layer Normalization)的核心思路。
RMSNorm 不关心均值,直接计算输入向量 $x$ 的均方根(Root Mean Square)作为缩放基准,一次性完成归一化。它的公式也因此轻巧了许多:
[
\text{RMSNorm}(x) = \frac{x}{\text{RMS}(x)} \cdot \gamma
]
[
\text{RMS}(x) = \sqrt{\frac{1}{d}\sum_{i=1}^{d} x_i^2 + \epsilon}
]
仅仅去掉了“减均值”和“加偏置”这两步,它实现了从 O(n) 到 O(n) 的常数级优化(减少运算步骤) 以及更小的参数量(去掉了 bias) ,在减少内存移动和显存占用方面效益显著。
因此,RMSNorm 成了包括 LLaMA、Mistral、DeepSeek、RWKV 在内的几乎近年所有爆款 LLM 的统一选择。开源社区和业界普遍认为,它的成功主要源于更少的参数量(减少显存占用)和更高效的 FLOPs(提升推理与训练速度)。在大型语言模型中,“效果差不多”时,“成本更低”的方案就是事实上的最优解。也有研究表明,全面采用 RMSNorm 的模型甚至能在下游任务上取得优于 LayerNorm 的性能。
五、后 RMSNorm 时代:归一化层能被“革掉”吗
随着 RMSNorm 成为新的标配,学术界也从未放弃过探索,打算将效率推向极致。顺着 RMSNorm 开启的简化思路,新的挑战者已经出现。
5.1 范式革命者:用激活函数代替归一化
既然 LayerNorm 表现出类似于 tanh 函数的非线性变换效果,那能否直接抛弃归一化层,用一个简单的激活函数来取代呢?这就是“De-norming”研究的核心思路。
由何恺明和 LeCun 等人在 CVPR 2025 上提出的 DyT (Dynamic Tanh) ,就是这条路上的一个里程碑。它以 tanh(αx) 结构为核心,用不到10行代码就能替换掉 LN 或 RMSNorm,能在 LLaMA、ViT 等不同架构的任务上达到甚至超越标准 Transformer 的性能。同时,因为 DyT 是逐元素计算,没有跨特征的规约操作,所以在推理和训练阶段都大大减少了 I/O 瓶颈,跑得更快。
这其实暗示了 RMSNorm 的原生实现本身就有效率瓶颈——虽然浮点运算量只占约 0.15%,但因为需要收集跨通道的统计数据,GPU 内核必须完成一次规约(reduce)操作和一次广播(broadcast)操作,其实际运行时间占比却可能高达 25%。这类操作的瓶颈不在算力(FLOPs),而在内存带宽(Memory-Bound),而 DyT 则巧妙地绕开了这道墙。
另一个更具理论高度的方向是 IBNorm(信息瓶颈归一化) 。它提出一个更深层的问题:现有的归一化方法(BN/LN/RMSNorm)都是“方差中心主义”的,只强制数据的方差为一,却没有控制模型学习什么样的信息。IBNorm 引入了可控的压缩操作,引导模型保留更多与预测任务相关的信息,并抑制冗余噪音。实验表明,IBNorm 在 LLaMA 等 LLM 及视觉模型上全面超越了 BN、LN 和 RMSNorm。
5.2 精度与硬件的深度协同
对于推理加速的极致追求,前沿研究也在精度和硬件层面不断探索。
在低精度训练领域,有前沿实验显示,只需在训练前微调一个额外的 RMSNorm 层,就能让模型在 1.58-bit 的极限量化精度下,依然保持极高的性能水平。而在硬件层面,有研究开始针对 RMSNorm 和 Softmax 这类非线性算子设计专门的硬件友好型近似加速方法。通过用查表(LUT)、对数减法等方式替代耗时的除法和开方计算,能在 FPGA 等边缘计算设备上获得显著的延迟和功耗优势。另一个名为 ARNorm 的新方法,则在极低比特计算领域,通过降低量化误差,在边缘 AI 设备上实现了精度与 32 位浮点数 RMSNorm 相当,同时更快、更省电的推理。
5.3 训练稳定性与异常值:神秘联系的揭晓
归一化技术还和训练稳定性,以及一个名为“Sinks”(异常值)的谜团有着千丝万缕的联系。
研究者们发现,在大模型推理时,会有少数几个 token 拥有异常高的注意力 logits,即注意力汇(attention sinks);同时,也会有某几个特征维度,在几乎所有 token 上都表现为异常高的激活值,即残差汇(residual sinks)。一项统一了二者视角的研究指出,这些“Sinks”并非单纯多余的噪声,而是通过与 Softmax、RMSNorm 等归一化操作协同工作,扮演着动态缩放(outlier-driven rescaling)的功能——它们实质上对其他非异常值成分进行了幅度缩放,从而维持了训练的稳定性与泛化能力。
这个发现给了我们一个全新的看待模型内部活动的方式:那些看似极端的、不稳定的异常值,实际上正是模型维持梯度平稳、防止激活爆炸或衰减的“动态稳压器”。
六、总结与展望
回顾 LayerNorm 与 RMSNorm 的发展历程,技术的跃迁指明了从“功能完备”到“极限效率”再到“范式革新”的清晰主线。
- LayerNorm:作为序列模型的奠基者,用均值和方差建立了深度网络训练稳定的基石。
- RMSNorm:凭借去掉均值、去掉偏置的大胆减法,成为现代 LLM 兼顾效率与效果的业界“标准答案”。
- 前沿探索:以 DyT 为代表的创新,正试图从根本上废除归一化层,使用更简单的元素级激活函数来开辟新的架构范式。
从 LN 到 RMSNorm 的演变,清晰地告诉我们一个道理:在大模型的世界里,理论的优雅往往是工程实践的先声,而极致的效率,才是最终的生存法则。
🧑💻 代码附录:手写 LayerNorm 与 RMSNorm
最后,让我们亲手实践一下。以下是用 Python 和 PyTorch 实现的 LayerNorm 和 RMSNorm。
import torch
import torch.nn as nn
class LayerNorm_Handcrafted(nn.Module):
def __init__(self, normalized_shape, eps=1e-5):
super().__init__()
self.gamma = nn.Parameter(torch.ones(normalized_shape))
self.beta = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
def forward(self, x):
# x shape: [B, L, D]
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
# Normalize: (x - mean) / sqrt(var + eps)
x_norm = (x - mean) / torch.sqrt(var + self.eps)
# Affine transform: scale and shift
return self.gamma * x_norm + self.beta
class RMSNorm_Handcrafted(nn.Module):
def __init__(self, normalized_shape, eps=1e-6):
super().__init__()
self.gamma = nn.Parameter(torch.ones(normalized_shape))
self.eps = eps
def forward(self, x):
# x shape: [B, L, D]
# RMS = sqrt(mean(x^2))
rms = torch.sqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
# Normalize: x / RMS
x_norm = x / rms
# Scale
return self.gamma * x_norm
class DyT_Handcrafted(nn.Module):
def __init__(self, num_features, alpha_init_value=0.5):
super().__init__()
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value)
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
x = torch.tanh(self.alpha * x)
return self.weight * x + self.bias📚 串联系列知识:回顾与展望
在我们构建的 LLM 知识体系中,归一化与残差连接是保证训练稳定的“幕后英雄”。
- 本系列前文回顾:
- Tokenizer(分词器) → Embedding(词嵌入)
- FFN 与 SwiGLU(知识存储器)
- Attention(MHA/MQA/GQA)与 KV Cache/PagedAttention
- MoE(混合专家) 架构
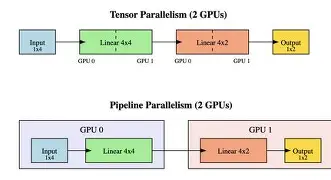
- 数据并行、张量并行与流水线并行
- Pre-Norm/Post-Norm & 残差连接(此前所作讲解)
- LayerNorm & RMSNorm(本篇内容)
作者
884705373@qq.com
相关文章