写在前面
终于,我们来到了 Transformer 最核心、最“灵魂”的部分——Attention(注意力机制)。
在前四篇文章中,我们一路走过 Tokenizer、Embedding、RoPE 和 FFN,已经大致摸清了数据在 LLM 中的流动路径。但有一个问题始终悬而未决:这些 Token 之间,到底是怎么“交流”的?
答案就是 Attention。如果说 FFN 是模型的“知识库”,那么 Attention 就是模型的“交流网”——它决定了在处理当前词时,模型应该“注意”到上下文中的哪些词,以及给每个词分配多大的“交流权重”。
正是因为有了 Attention,LLM 才能理解“苹果很好吃”中的“很”是在修饰“好吃”,而不是在修饰“苹果”;才能在做翻译时,把英文的“bank”根据上下文正确地译为“银行”或“河岸”。
今天这篇文章,我们将一道一道地剖开 Attention 的“黑箱”,从最基础的 MHA(多头注意力) 开始,讲清楚它内部的 Q、K、V 到底在做什么;然后深入工程实践中最重要的两个变体——MQA(多查询注意力) 和 GQA(分组查询注意力) ;最后,我们会触及这个领域的最前沿——MLA(多头潜在注意力) 和最新的注意力优化技术。
这篇文章可能会是整个系列中信息密度最高的一篇,因为它涉及 LLM 推理优化中最关键的两个概念:KV Cache 和显存瓶颈。
一、为什么 Attention 是 Transformer 的灵魂?
1.1 如果没有 Attention:一个“健忘”的模型
想象一下,你要写一个程序,让它读完一句话后,回答“这句话的主语是谁?”。
如果没有 Attention,你能怎么做?你可能会把整个句子压缩成一个固定长度的向量(比如 LSTM 或 GRU 的做法),然后用这个向量来回答问题。但问题在于:把一句话压缩成一个向量,必然会丢失大量细节。当句子变长时,模型就像一个人拼命想记住一个长故事,却只有一张便签纸——写着写着,前面的内容就全忘了。
Attention 的革命性在于:它放弃了“压缩”的执念。 Attention 允许模型在处理每一个词时,直接“回看”整个输入序列,并根据需要从序列中的任意位置提取信息。它不是把故事记在便签纸上,而是让模型能够随时把目光投向故事的任意一页。
1.2 Attention 的直觉:相似度驱动的“回溯”
Attention 计算的核心可以用一句话概括:对于当前的 Token,找出上下文中所有与它“相似”的 Token,然后把这些 Token 的信息加权融合过来。
这里的“相似”,不是语义上的“苹果和水果相似”,而是经过投影后,两个向量在高维空间中的点积相似度。
举个例子,当模型处理句子“小猫在追一只老鼠,它跑得很快”中的“它”字时,Attention 会自动发现:“它”的 Query 向量,与前面“小猫”的 Key 向量之间的点积非常大。于是,“小猫”的信息会被分配很高的权重,融入到“它”的表示中,这样模型就知道“它”指的是“小猫”。
整个 Attention 机制就像是给每个 Token 配了一部“时空穿梭机”:每处理一个新词,都可以自由地回到过去的任意时刻,把那里的信息“提取”过来用。
二、Self-Attention 的数学拆解
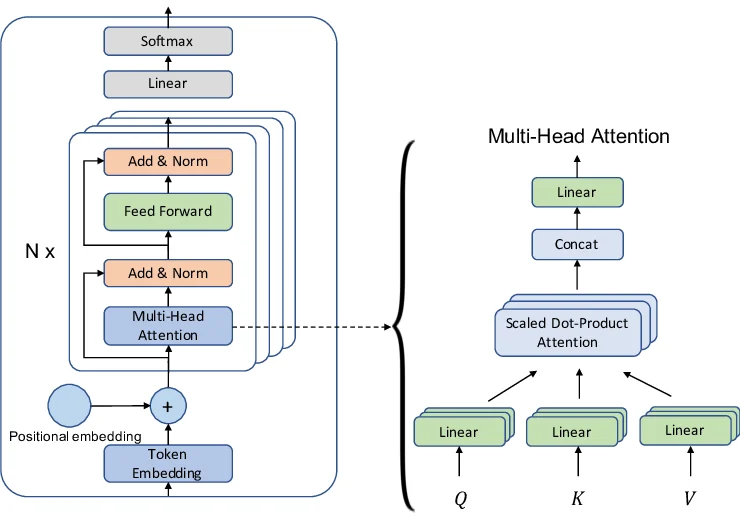
2.1 Q、K、V:三种身份,各司其职
标准 Self-Attention 的计算,依赖于三个核心矩阵:Query(Q)、Key(K)、Value(V)。
对于输入序列中的每一个 Token,它的 Embedding 向量 x 会通过三个不同的权重矩阵(W_Q、W_K、W_V)投影,生成三个全新的向量:
- Q(Query,查询向量) :代表“我正在寻找什么”。这是当前 Token 发出的“需求信号”。
- K(Key,键向量) :代表“我是什么”。这是每个 Token 发出的“身份标签”。
- V(Value,值向量) :代表“我的内容是什么”。这是每个 Token 实际要传递的信息。
用一个简单的比喻来理解:
你走进一家图书馆(输入序列),想找关于“罗马帝国”的书(Query)。每本书的封面上都贴着关键词标签(Key)。你扫一眼所有标签,发现某本书的标签是“罗马帝国”,与你的 Query 高度匹配,于是你把它从书架上取下来,阅读它的内容(Value)。你最终获得的知识,就是所有匹配程度加权后的 Value 之和。
2.2 Attention 计算四步走
第一步:生成 Q、K、V。对于每个 Token,用三个矩阵投影:
Q = x · W_Q
K = x · W_K
V = x · W_V第二步:计算注意力分数。用当前 Token 的 Q 去和所有 Token 的 K 做点积,得到一个“匹配程度”矩阵:
Score = Q · K^T第三步:归一化。用 Softmax 将分数转换为 0 到 1 之间的概率分布(全部加起来等于 1)。为了防止点积值过大导致 Softmax 梯度消失,通常还会除以维度的平方根:
Attention_Weights = softmax(Score / √d_k)第四步:加权求和。用这些权重,对所有 Token 的 V 进行加权求和,得到当前 Token 的最终输出:
Output = Attention_Weights · V这四步,就是 Attention 的全部数学。虽然看起来简单,但正如那句名言所说:“简单,但不简陋。”
2.3 Masked Self-Attention:让模型学会“预知未来是作弊”
在训练 LLM 做文本生成时,我们会刻意遮住未来的信息。因为如果模型能看到后面的词,那“预测下一个词”就变成开卷考试了——毫无意义。
Masked Self-Attention 的做法是:在计算 Softmax 之前,将 Q 与未来位置的 K 的点积分数设为负无穷(-∞)。这样经过 Softmax 后,未来位置的注意力权重就变成 0,模型只能看到当前及之前的内容。这个过程叫做因果注意力(Causal Attention),也是“自回归生成”的核心约束。
三、MHA:让模型戴上“多副眼镜”看世界
3.1 一个头的局限
单独的 Self-Attention 有一个天然的问题:它只能捕捉一种“相关性模式”。比如在处理“银行”这个词时,一个注意力头可能需要同时判断它是指“金融机构”还是“河岸”,还要同时处理语法关系和指代消解——把所有任务压在一个头上,模型会非常吃力。
3.2 MHA 的方案:多头,各看各的
MHA(Multi-Head Attention,多头注意力) 的解决方案非常直觉:并行地计算多个独立的 Attention,每个头使用自己的一套 W_Q、W_K、W_V 权重。
具体做法是:
- 将 Q、K、V 拆分成 h 个头(每个头的维度为 d_head = d_model / h)
- 每个头独立执行一次完整的 Self-Attention 计算
- 将所有头的输出拼接起来,再经过一个线性变换(W_O)融合
用公式表示:
MultiHead(Q, K, V) = Concat(head_1, head_2, ..., head_h) · W_O3.3 MHA 的优势:多角度观察
每个注意力头就像戴了一副不同度数或不同颜色的眼镜来观察同一个句子。有的头关注句法(比如名词和形容词的关联),有的头关注指代(比如代词和它指代的名词),有的头关注长距离依赖(比如段落首尾的呼应)。
这种“多角度观察”让 MHA 拥有了远超单头注意力的表达能力。这也是为什么原版 Transformer 和早期 GPT 都采用了 MHA——它确实好用。
3.4 MHA 的代价:KV Cache 的隐形成本
然而,MHA 有一个在推理时会变成“显存怪兽”的工程问题——KV Cache。
在自回归生成中,每生成一个新 Token,我们都需要计算它和之前所有 Token 的 Attention。如果每次从头算一遍,计算量会以 O(n²) 的速度爆炸。
KV Cache 就是为了解决这个问题而生的:把已经算过的所有 Token 的 Key 和 Value 向量保存下来,生成下一个 Token 时直接复用,只计算当前 Token 的 Q、K、V,然后用当前的 Q 去和缓存的 K 计算 Attention,最后更新 KV Cache。
问题在于:MHA 有多少个头,每个 Token 就需要缓存多少组 K 和 V。对于 LLaMA-7B 来说,它有 32 个头,每个头的维度是 128,所以每个 Token 的 KV Cache 大小为:
32 头 × 128 维 × 2(K 和 V)× 2 字节(FP16)= 16 KB / Token这看起来不多。但想象一下,当批处理大小(batch size)变大、序列长度变成 128K 甚至 1M、层数叠加到几十层时,KV Cache 会迅速膨胀成推理显存的最大头——在某些场景下,KV Cache 甚至占了总显存的 90% 以上。
于是,压缩 KV Cache 就成了 LLM 推理优化的核心战场。MQA 和 GQA 正是在这种需求下诞生的。
四、MQA:极致的 KV Cache 压缩
4.1 MQA 的核心思想:所有头共享 KV
MQA(Multi-Query Attention,多查询注意力) 的想法非常简单直接:让所有注意力头共享同一份 Key 和 Value,只有 Query 保持独立。
在 MQA 中,每个 Token 仍然有多个 Q 头(每个头看到的世界不同),但只有一份 K 和 V。既然 K 和 V 是多头共享的,那 KV Cache 的大小就只剩下 MHA 的 1/h(h 为头数)。如果头数是 32,KV Cache 的占用直接缩水 32 倍!
这在实际工程中带来的影响是巨大的:推理速度提升,显存占用大幅下降,能够支持更长的上下文和更大的批处理。
4.2 MQA 的代价:表达能力的退化
天下没有免费的午餐。MQA 虽然压缩了显存,但也付出了代价:所有头在看同一个 K 和 V 时,模型的表达能力会下降。
因为每个头不再有自己的专属“视角”来审视 K 和 V,它们被迫从同一份信息中寻找各自需要的部分。实验表明,MQA 在同等参数量下,效果普遍略逊于 MHA。虽然差距不大,但对于追求极致性能的大模型来说,这个损失不太能接受。
4.3 MQA 的应用
MQA 的代表性应用是 Google 的 PaLM 模型,以及一些注重极致推理效率的轻量级模型。但在追求能力上限的大规模开源模型中,MQA 逐渐被一个“折中方案”取代——GQA。
五、GQA:效率与效果的黄金平衡
5.1 GQA 的方案:分组共享
GQA(Grouped Query Attention,分组查询注意力) 是 MHA 和 MQA 之间的“甜蜜点”。
它的做法是:将所有的 Query 头分成若干组(比如 8 个头分成 2 组或 4 组),同一组内的 Query 头共享同一份 Key 和 Value。
假设模型有 32 个头,我们将其分为 8 组(每组 4 个头)。那么对于每个 Token,只需要缓存 8 组 K 和 V。与 MHA(32 组 KV)相比,KV Cache 缩小为 1/4;与 MQA(1 组 KV)相比,又保留了更多的表达能力(8 种不同的 K 和 V)。
5.2 GQA 的由来与推导
GQA 并非凭空出现,它的提出动机非常直白:在模型规模和序列长度都不断增长的今天,MHA 的 KV Cache 已经不堪重负;MQA 的压缩又让模型能力下降太多。我们需要一个可以调节压缩比的方案。
GQA 的“组数”成了一个可调的超参数。组数越小(甚至等于 1,即 MQA),压缩率越高,推理越快;组数越大(甚至等于头数,即 MHA),表达能力越强,但显存占用也越大。LLaMA-2 70B 采用了 8 组 GQA(头数 64,分组数 8),在几乎不损失精度的情况下,极大地提升了推理效率。
5.3 GQA 为什么成为“标配”?
因为它在以下三个维度上都取得了很好的平衡:
- 训练稳定性:GQA 的训练曲线比 MQA 更稳定,不易出现能力退化。
- 推理效率:相比 MHA,KV Cache 显著缩减,长文本和批处理场景下显存优势明显。
- 模型性能:在同等参数量下,GQA 的性能非常接近 MHA,远超 MQA。
基于这些原因,GQA 迅速成为现代 LLM 的事实标准:LLaMA-2/3 在大尺寸模型上采用 GQA,Qwen、Mistral、Gemma 等模型也纷纷跟进,甚至在较小的模型上也引入了 GQA。可以说,在 2024 到 2025 年间发布的商业级大模型中,GQA 已经是“默认配置”。
六、MHA、MQA、GQA 横向对比
为了让你对这三种方案的差异有一个最直观的感受,我们把它们的关键数据放在一张表里:
| 特性 | MHA | MQA | GQA |
|---|---|---|---|
| KV 份数 | h(头数) | 1 | g(组数,1 < g < h) |
| KV Cache 大小 | 最大 | 最小(1/h) | 居中(g/h) |
| 推理显存占用 | 高 | 极低 | 中低 |
| 表达能力 | 最强 | 最弱 | 接近 MHA |
| 训练难度 | 中等 | 略高 | 中等 |
| 代表模型 | 原版 Transformer、GPT-3 | PaLM、部分小模型 | LLaMA-2/3、Qwen、Mistral |
| 适用场景 | 科研、小规模推理 | 极致资源受限 | 通用生产环境 |
选择建议:
- 做学术研究、追求极致的模型能力上限,且推理资源充足 → MHA(或较高组数的 GQA)
- 想用大模型做 API 服务,需要高并发和长上下文 → GQA(默认选择)
- 榨干边缘设备(手机、嵌入式)的每一滴性能 → MQA(或 GQA 组数为 1)
七、前沿探索:从 GQA 到 MLA 再到未来
故事到了 GQA,Attention 的架构似乎已经趋于完美。但研究者们并没有停下脚步——随着模型上下文窗口突破 100 万 Token,哪怕是 GQA 也开始显得“臃肿”。
7.1 DeepSeek MLA:低秩压缩的奇迹
如果说 MQA 是用“共享”来压缩,那么 DeepSeek 提出的 MLA(Multi-head Latent Attention,多头潜在注意力) 就是用“降维”来压缩。
MLA 的核心洞察是:Key 和 Value 矩阵中其实有大量的冗余信息,我们可以用一个低秩的“隐变量(Latent Vector)”来压缩它们。
具体来说,MLA 不再为每个 Token 存储完整的 K 和 V 向量。它在计算 K 和 V 时,先将输入投影到一个维度非常小的“潜在空间”(比如 64 维),然后用这个小向量在每次使用时动态解压出完整的 K 和 V。由于只需要缓存那个小小的潜在向量,KV Cache 的大小又被压缩了一个数量级。
更关键的是,MLA 的解压过程可以与 RoPE 巧妙结合——DeepSeek 团队设计了一种解耦的旋转位置编码策略,确保在低秩压缩的同时,位置信息依然被准确注入。
结果是什么?DeepSeek-V2 用 MLA 实现了同时在训练和推理阶段的大幅效率提升,KV Cache 仅为传统 MHA 的 5%~10%。这也是 DeepSeek-V3 能够以 37B 激活参数匹敌更大规模稠密模型的秘密武器之一。
7.2 其他前沿方案一览
除了 MLA,2025 年到 2026 年间还涌现了许多旨在进一步优化 Attention 的工作:
(1)Lightning Attention:融合 FlashAttention 和计算重塑
由 RWKV 团队提出,Lightning Attention 在单内核中高效处理 Attention 矩阵的所有元素,特别优化了多 GPU 环境下的通信模式。在 3B 规模的密集模型上推理速度比 FlashAttention-3 快两倍以上。
(2)Beyond KV Caching:抛弃缓存的激进尝试
DeepSeek 的 RetrievalAttention 和 ContextParallel 尝试用稀疏检索和并行上下文分片来取代传统的稠密 KV Cache。而 LLaMA 社区的 RocketKV 则在不用闪存卸载的情况下,让 7B 模型在单张 4090 上就能处理百万 Token 的长上下文。
(3)MagicPIG:用 LSH 做近似检索
MagicPIG 的灵感来源于计算机科学中经典的局部敏感哈希(LSH)——把 Key 向量哈希到桶中,生成每个 Token 时只去相关的桶里找 Key,而不是用 Q 去和所有缓存的 K 做点积。这种方法把 Attention 的 O(n²) 复杂性降到了 O(n log n),特别适用于超长上下文场景。
(4)硬件与算法协同设计
随着存内计算(PIM,Processing-in-Memory) 芯片的成熟,一些研究者开始探索将 Attention 计算完全卸载到新的硬件架构上。2025 年的一篇论文综述了如何利用 PIM 打破 Attention 的“内存墙”瓶颈,代表了软硬结合的新方向。
八、FlashAttention:不改变架构,却改变一切的算法
在结束 Attention 的话题之前,必须花一点篇幅致敬另一个“幕后英雄”——FlashAttention。
前面讨论的 MQA、GQA、MLA,都是从架构层面压缩 KV Cache 或参数量。而 FlashAttention 走的是另一条路:不改变 Attention 的数学定义,只改变它在 GPU 上的计算方式。
8.1 问题的根源:内存墙
Attention 公式中有一个“噩梦级”的操作:Q · K^T 会产生一个 [seq_len, seq_len] 的矩阵。当序列长度达到 128K 时,这个矩阵有多大?
- 假设用 FP16 存储:128K × 128K × 2 字节 ≈ 32 GB
- 即使是 H100 的 80GB 显存,单是存这个矩阵就已经捉襟见肘。而实际的推理中,还有模型参数、KV Cache、中间激活值要放。
传统实现会将整个 Attention 矩阵写出到 GPU 的 HBM(高带宽显存)中,计算完 Softmax 后再读回来。这种频繁的“写入-读取-写入”造成了推理的严重瓶颈——算力在等待数据搬运,GPU 核心大量闲置。
8.2 FlashAttention 的解法:分块计算 + 在线 Softmax
FlashAttention 做了两件非常聪明的事:
- 分块计算(Tiling):不一次性生成整个 Attention 矩阵,而是将 Q 和 K 分成小块,一块一块地计算,用 SRAM(片上缓存)临时存储中间结果,算完就扔,绝不让大矩阵完整地出现在 HBM 中。
- 在线 Softmax:推导出一种数学上等价的 Softmax 递推公式,使得每一块的计算可以独立进行,不需要等待全部数据就位。
效果怎样?显存占用从 O(n²) 降低到 O(n)。在 128K 长序列上,FlashAttention 相比标准实现,显存占用减少 80% 以上,速度提升 5-8 倍。
如今,FlashAttention 已经是所有主流框架(PyTorch、vLLM、Hugging Face Transformers)的默认后端。由 FlashAttention 原作者创办的 FlexAI(后更名为 Aither) 等公司,甚至开始将这种“分块 + 融合 Kernel”的思想做成专用的 AI 云服务,进一步推动了整个行业的效率革命。
九、总结与展望
9.1 Attention 演进路线全景图
让我们用一张时间线表格来回顾 Attention 架构的演化:
| 时间 | 方案 | 核心创新 | 对推理的影响 |
|---|---|---|---|
| 2017 | MHA | 多头并行,多角度关注 | 构建了 Transformer 基础,但 KV Cache 巨大 |
| 2019 | MQA | 所有头共享 KV | KV Cache 降至 1/h,但能力有损 |
| 2022 | FlashAttention | 分块计算 + IO 优化 | 不改变架构,但训练推理速度数倍提升 |
| 2023 | GQA | 分组共享 KV | 灵活调节压缩比,能力接近 MHA,成为标配 |
| 2024 | MLA | 低秩压缩 KV,结合 RoPE | KV Cache 再压缩一个数量级,迈向超长上下文 |
| 2025+ | 专用硬件协同 | 存内计算(PIM)等 | 软硬结合打破“内存墙”的终极方案 |
9.2 串联系列知识:Attention 在 LLM 中的位置
回顾我们五篇文章构建的完整数据流:
- Tokenizer → Token ID 序列
- Embedding → 高维语义向量
- RoPE → 向量加入相对位置旋转
- Pre-Norm(RMSNorm) → 稳定数值分布
- Attention(GQA/MLA) → Token 间的信息交互、上下文感知 ← 我们在本篇学到的内容
- 残差连接 → 保留原始信息
- Pre-Norm(RMSNorm) → 再次归一化
- FFN(SwiGLU / MoE) → 知识存储与非线性变换
- 残差连接 → 保留信息
至此,一个完整的 Transformer Block 的所有组件都已讲解完毕。
9.3 未来趋势
- 超长上下文常态化:从 128K 到 1M 甚至无限长度,Attention 的稀疏化和压缩机制将持续进化。
- MLA 及更高效的压缩方案:DeepSeek 已经证明低秩压缩的巨大潜力,后续将有更多类似思路出现。
- 存内计算(PIM)落地:当算法优化接近极限,真正的下一次飞跃可能来自硬件革命。
- 动态路由的 Attention:不固定使用所有头,而是根据输入动态激活部分头——Attention 版的“MoE”。
- 多模态注意力统一化:文本、图像、语音、视频的 Attention 机制逐渐收敛到同一套框架。
作者
884705373@qq.com
相关文章