写在前面
在上一篇文章中,完整地走了一遍 LLM 的架构全景图。那篇文章提到:原始文本进入模型的第一步,就是经过 Tokenizer 的处理。
但说实话,当时只用几段话带过 Tokenizer,实在有点“亏待”这位默默无闻的功臣。Tokenizer 虽然看起来只是做“切词”这种简单的工作,但它对整个模型的性能、效率甚至公平性都有着深远的影响。
今天这篇文章,我们就来专门聊一聊 Tokenizer——这位文本的“翻译官”、大模型的“守门人”。我会从它的基本原理讲起,深入到三种主流分词算法的对比,再到字节级 BPE 的工程实践。
一、为什么需要 Tokenizer?——一个看似简单却暗藏玄机的问题
1.1 Tokenizer 的“本职工作”
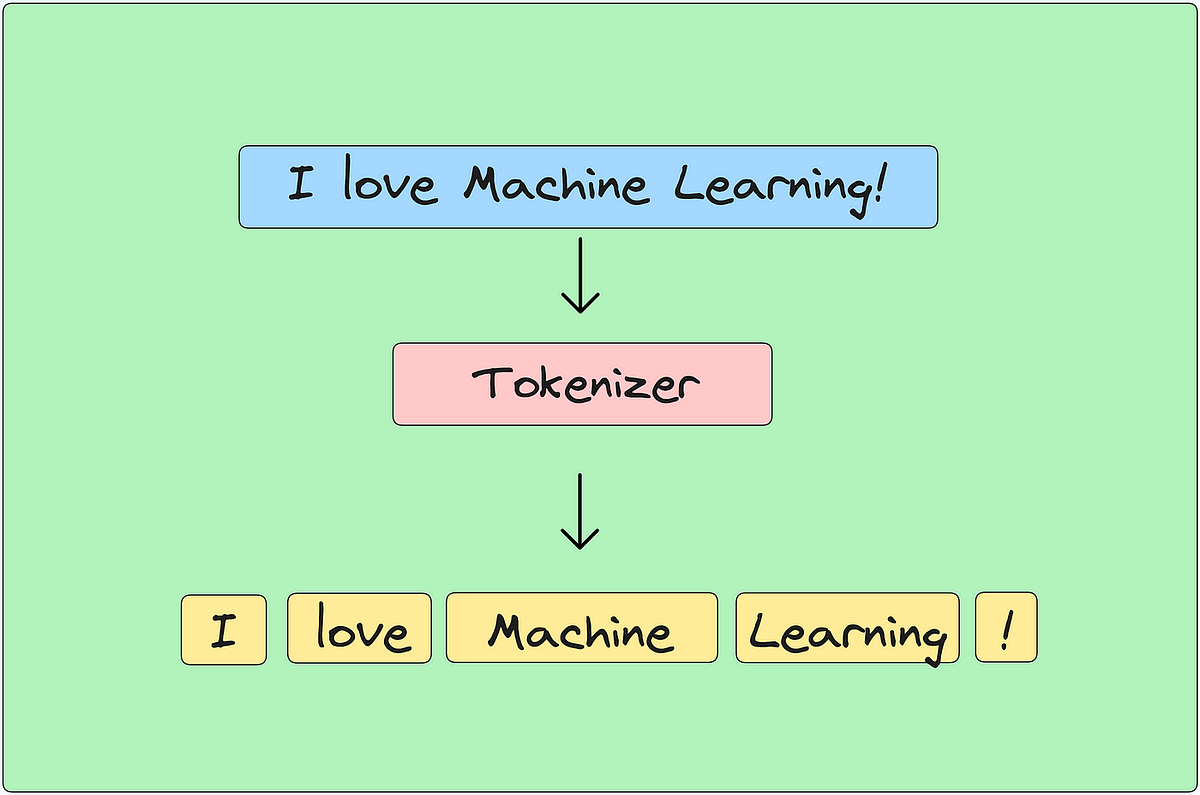
大模型本质上是一堆矩阵运算的集合,它不懂汉字、字母或标点符号,只能处理数字。Tokenizer 的工作,就是把人类写的文本转换成模型能“吃”的数字序列。
从技术上讲,Tokenization 是训练 LLM 的第一步。LLM 分析 Token 之间的语义关系——比如它们一起出现的频率,或者是否出现在相似的上下文环境中。有了这些模式和关系,模型才能根据输入的 Token 序列,预测并生成下一个 Token。
举个例子:
输入:"我爱大语言模型"
↓ Tokenizer 处理 ↓
Token 序列:["我", "爱", "大", "语言", "模型"]
↓ 映射到词表 ↓
Token ID:[231, 452, 789, 1023, 88]但问题来了:怎么“切”才是最好的? 这就是 Tokenizer 设计的核心问题。
1.2 三种粒度的取舍
在 NLP 的发展史上,研究者们尝试过三种不同粒度的分词方案:
| 分词粒度 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 单词级 | 按空格和标点拆分 | Token 数量少,计算量小 | 词表巨大(几十万甚至上百万),OOV 问题严重 |
| 字符级 | 按单个字符拆分 | 词表极小(几十到几百个),完全覆盖所有输入 | Token 序列超长,计算量大,语义信息被稀释 |
| 子词级 | 介于单词和字符之间 | 平衡词表大小和序列长度,能处理 OOV | 算法相对复杂,语言适配有差异 |
子词级分词是目前大语言模型的主流选择。它既不像单词级那样遇到生僻词就束手无策,也不像字符级那样把句子拆得稀碎。通过将常见词保留为完整 Token,将罕见词拆分为有意义的子词片段,Tokenizer 在效率和语义完整性之间找到了一个“甜蜜点”。
1.3 一个经典的例子
来看 BERT 和 GPT 两种分词器的实际表现:
输入:"transformer architecture"
GPT(BPE)分词:["transform", "er", "architecture"]
BERT(WordPiece)分词:["transform", "##er", "arch", "##itecture"]可以看到,两者都把“transformer”拆分成了“transform”和“er”,把“architecture”拆成了更小的片段。这种拆分方式让模型能够理解:即使没见过“transformer”这个词,但知道“transform”和“er”各自的意思,也能大致推断出“transformer”的语义。
二、三大主流算法:BPE、WordPiece、SentencePiece
如果说 Tokenizer 是整个模型的第一道工序,那么分词算法就是这道工序的核心引擎。目前主流的三种子词分词算法,各有各的设计哲学和应用场景。
2.1 BPE(Byte Pair Encoding):从压缩算法到分词神器
BPE 的诞生其实和自然语言处理没什么关系——它最初是 1994 年提出的一种数据压缩算法,后来被研究者发现“诶,这东西用来做分词好像也不错”,于是摇身一变,成了今天大语言模型领域使用最广泛的分词算法。
BPE 的核心逻辑非常简单:从字符开始,反复合并出现频率最高的相邻字符对,直到达到预设的词汇表大小。
具体流程如下:
- 初始化:将训练语料中的每个词拆成字符序列,末尾加一个特殊符号(如
</w>)表示词结束。 - 统计频次:计算所有相邻字符对出现的频率。
- 合并:找出频率最高的那一对,将它们合并成一个新的符号,加入到词表中。
- 循环:重复步骤 2-3,直到达到预设的词汇表大小(比如 32000)。
来看一个简化的例子。假设训练语料中有以下词汇及频率:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)BPE 的合并过程大概是这样的:
- 初始词汇表:
["b", "g", "h", "n", "p", "s", "u"] - 统计发现
"u"+"g"出现最频繁(在 hug、pug、hugs 中),合并为"ug" - 接下来
"h"+"ug"出现最频繁,合并为"hug" - 继续合并,直到词表满……
最终,模型学到的词汇表中既有完整的常见词(如“hug”),也有高频子词(如“ug”),还有基础字符。这种设计让 BPE 能够天然地处理未登录词(OOV) ——即使遇到训练时没见过的词,也可以通过组合已知的子词来编码。
BPE 的优势:
- OOV 问题解决得好:理论上任何词都可以用基础字符组合表示
- 词汇量可控:通过设置合并次数,精确控制词表大小
- 多语言支持不错:字节级 BPE 更是可以统一处理多语言
BPE 的不足:
- 对中文支持有限:中文没有天然的分隔符,合并效果不如英文自然
- 可能产生不完整的词:贪心合并策略未必是语义上的最优选择
目前,OpenAI 的 GPT 系列、Meta 的 LLaMA 系列、阿里的 Qwen 系列等主流模型,都采用了 BPE 或其变体作为分词方案。
2.2 WordPiece:BERT 背后的“单词拼图”
WordPiece 是 Google 为 BERT 专门开发的分词算法。它的基本思路和 BPE 类似——都是从字符开始逐步合并,但合并的选择标准不同。
BPE 的合并策略是“选出现频率最高的那一对”;而 WordPiece 的策略是“选能让训练语料整体概率提升最大的那一对”——也就是说,它基于最大似然估计来做决策,而不是简单的频率统计。
另一个显著的区别是标记方式。WordPiece 使用 ## 前缀来标记子词:
"playing" → ["play", "##ing"]
"unhappiness" → ["un", "##happiness"] 或 ["un", "##happy", "##ness"]## 的含义是“这不是一个词的开始,而是前面某个词的延续”。这个设计让模型能明确区分“一个词的第一个子词”和“后续子词”,对于英文这种高度依赖词缀的语言特别有用。
WordPiece 的拆分规则也更严格。如果当前词在词汇表中找不到,WordPiece 会尝试更长的子词匹配;而 BPE 则会贪婪地合并子词直到完成。这使得 WordPiece 的拆分结果往往比 BPE 更“保守”,倾向于保留更长的语义单元。
WordPiece 的优势:
- 对英文语义的捕捉更精准
- 拆分规则严格,适合理解类任务(如 BERT 的 MLM)
WordPiece 的不足:
- 跨语言泛化能力较弱,对中文需要额外的预分词处理
- 训练速度比 BPE 慢
2.3 SentencePiece:打破空格“霸权”的多语言方案
BPE 和 WordPiece 都有一个共同的“盲点”:它们都依赖空格作为词边界的预判断。这对于英文等有天然空格分隔的语言来说没有问题,但对于中文、日文、泰文等无空格语言,就需要额外预处理——要么先分词再丢给 Tokenizer,要么按字切分。
于是,SentencePiece 应运而生。它最核心的创新是:将输入文本视为 Unicode 字符序列,完全忽略空格的存在。
这意味着 SentencePiece 对任何语言都是“一视同仁”的。无论是英文、中文还是日文,在它眼里都只是一串 Unicode 字符流。它既不依赖空格,也不需要预先分词,直接从原始文本中学习子词单元。
SentencePiece 还内置了对 BPE 和 Unigram 两种算法的支持,本质上是一个“分词框架”而非单一算法。其中,Unigram 是一种基于概率的算法,与 BPE 的贪心策略不同,它通过期望最大化(EM)算法迭代优化词表,理论上更加优雅。不过,Unigram 的实现复杂度较高,在实践中 BPE 模式仍然更受欢迎。
SentencePiece 的优势:
- 语言无关性:完美支持中文、日文等无空格语言
- 可逆转换:可以从 Token 序列无损还原原始文本
- 一体化处理:训练、编码、解码都在同一个框架内完成
SentencePiece 的不足:
- 训练速度相对较慢
- 模型文件较大
LLaMA、Mistral、Gemma、T5、ALBERT 等众多模型都使用了 SentencePiece 作为分词方案。
2.4 三种算法的横向对比
| 特性 | BPE | WordPiece | SentencePiece |
|---|---|---|---|
| 核心策略 | 高频字符合并 | 最大似然合并 | 语言无关的 Unicode 处理 |
| 语言支持 | 英文为主,多语言尚可 | 英文为主 | 多语言原生支持 |
| 空格处理 | 依赖空格 | 依赖空格 | 不依赖空格 |
| 训练速度 | 快 | 中等 | 慢 |
| 代表模型 | GPT, LLaMA, Qwen | BERT | LLaMA, T5, ALBERT |
| 特殊标记 | 无特殊标记 | ## 前缀标记子词 | 支持自定义特殊标记 |
从表格可以看出,不同算法的选择往往取决于模型的目标场景:理解类任务多用 WordPiece,生成类任务多用 BPE,多语言场景则倾向于 SentencePiece。
三、字节级 BPE:现代 LLM 的“真·标配”
3.1 从字符级到字节级的进化
传统的 BPE 是在字符层面上进行合并的。但字符的边界是人为定义的(比如 Unicode 字符),不同语言的字符集大小差异很大,而且总有一些生僻字符可能超出词表的覆盖范围。
为了解决这个问题,研究者们提出了字节级 BPE(Byte-level BPE) :直接在 UTF-8 编码的字节序列上应用 BPE 算法,而非在字符级别上操作。
UTF-8 编码有一个美妙的性质:任何字符都可以表示为 1 到 4 个字节。整个 UTF-8 的字节空间只有 0 到 255 共 256 种取值。这意味着,字节级 BPE 的词表基础就是这 256 个字节——理论上,它可以表示任意 Unicode 字符,无论这个字符有多生僻。
3.2 字节级 BPE 的运作机制
以 Qwen3 为例,它的分词器采用了字节级 BPE 实现,核心架构包含三个组件:
- 字节编码器:将输入文本转换为 UTF-8 字节序列
- BPE 合并表:存储训练得到的字节合并规则
- 词汇映射表:维护 token_id 与字节序列的对应关系
这种架构使得模型可以高效处理混合语言文本,尤其是在包含专业术语和特殊符号的场景下表现优异。
举个例子,处理中文字符“你好”:
- SentencePiece(字符级 BPE):需要 1 次合并(字符级)
- Qwen3(字节级 BPE):需要处理 6 个原始字节,约 5 次字节级合并
虽然步骤更多,但字节级 BPE 换来的好处是巨大的:完全覆盖所有字符,没有任何字符会被标记为“未知” 。在字节级 BPE 中,OOV(Out of Vocabulary)这个概念几乎消失了——因为任何文本都可以用 256 个基础字节组合表示。
3.3 字节级 BPE 成为“标配”的原因
如今几乎所有主流的解码器模型都采用 BPE 作为分词算法,而字节级 BPE 更是成为事实上的“标配”。原因有三:
- 全覆盖性:256 个基础字节可以表示任意 Unicode 字符,彻底解决了 OOV 问题
- 训练高效:相比于训练一个语言模型需要数万亿 Token,训练一个好的 BPE 分词器只需要几百万 Token
- 工程成熟:Hugging Face 的
tokenizers、OpenAI 的tiktoken、Google 的sentencepiece等库提供了成熟易用的实现
四、从“静态词典”到“智能适配”:最新研究前沿
如果说前三章讲的是“已经成熟的经典技术”,那么这一章要聊的就是“正在发生的未来”。Tokenizer 领域近两年的研究异常活跃,主要沿着以下几个方向推进。
4.1 多语言公平性:Tokenizer 不只是技术问题
2025 年一项覆盖 200 多种语言的大规模研究发现:拉丁字母语言的分词效率远高于非拉丁字母和形态复杂的语言。
具体来说,以英语为基准(RTC = 1.0),很多非拉丁语言的“相对分词成本”(Relative Tokenization Cost)高达 3 到 5 倍。这意味着,说这些语言的用户,在使用同样的 LLM 时,需要消耗更多 Token、更多算力、更多费用,而且有效上下文窗口也被大幅压缩。
这不仅仅是技术问题,更是一个基础设施层面的公平性问题。研究者呼吁,未来的 Tokenizer 设计应该更多地考虑语言形态学的多样性,从源头减少这种“计算上的不公平”。
4.2 通用多语言 Tokenizer:一个 Tokenizer 统治所有语言?
Cohere 团队在 2025 年提出了一个有趣的想法:在预训练阶段就使用一个覆盖更多语言的通用 Tokenizer,即使这些语言并不是主要的预训练语言。
他们的实验表明:使用通用 Tokenizer 可以让模型在后续适应新语言时,胜率提升高达 20.2%——即使在 Tokenizer 和预训练中完全没见过的语言上,也能获得约 5% 的胜率提升。这种“语言可塑性”(language plasticity)的发现,为低成本扩展 LLM 的语言覆盖范围提供了新的思路。
4.3 词表适应:让老 Tokenizer 学会新词
由于 Tokenizer 的设计在模型训练之前就固定了,从头训练一个新 Tokenizer 的代价极其高昂。那么,有没有办法在不重新训练整个模型的情况下,让 Tokenizer“学会”新词呢?
AdaptBPE 提出了一种后训练适应策略:选择性替换词表中利用率低的 Token,用目标领域或语言中更相关的 Token 来替代。实验表明,这种方法能在保持词汇表大小不变的情况下,显著提升特定领域的编码效率,相当于一种“词表微调”过程。
类似地,VRCP(Vocabulary Replacement Continued Pretraining) 也提出通过词表替换加继续预训练的方式,高效地将英语中心的模型适配到其他语言。
4.4 抛弃 Tokenizer:字节级模型的新浪潮
这是当前 Tokenizer 领域最激进也最令人兴奋的方向:完全抛弃 Tokenizer,让模型直接处理原始字节流。
2026 年 ICLR 收录的 ByteFlow 是这一方向的代表。它引入了一种新的层次化架构,让模型学习对原始字节流进行自适应的压缩式分段——基于潜在表示的编码率动态决定在哪里切分,而不是依赖预先定义好的静态词表。实验显示,这种压缩式分段策略在性能上不仅超越了 BPE 模型,还超越了之前所有的字节级架构。
另一个有趣的工作是 Kathleen,一个仅 73 万参数、不使用 Attention、也不使用 Tokenizer 的文本分类模型。它直接在 UTF-8 字节上通过频域处理来学习,在 IMDB 情感分类任务上甚至超过了 16 倍参数量的传统模型。
此外,MambaByte 将 Mamba 状态空间模型适配到字节序列上,SpaceByte 则在字节级解码器上取得了接近 Token 级 Transformer 的性能。这一系列工作传递了一个清晰的信号:端到端的、无 Tokenizer 的模型不仅是可行的,而且正在变得越来越有竞争力。
4.5 视觉 Tokenizer:多模态大模型的“新战场”
随着多模态大模型的崛起,“如何把图像、视频、音频变成 Token”成了新的研究热点。2025 年,离散 Tokenizer 领域的进展尤为显著。
视觉 Tokenizer 的核心挑战:用于图像生成的 Tokenizer(如 VQ-VAE 风格)擅长捕捉低级感知细节,但缺乏高级语义理解能力;用于理解的 Tokenizer 则相反。如何在一个 Tokenizer 中统一两者?
DualToken 尝试用双重视觉词汇表来解决这个问题。Apple 团队提出的 ATOKEN 则号称是首个能够在所有主要视觉模态(图像、视频、3D)上进行统一处理的视觉分词器。TA-Tok(Text-Aligned Tokenizer) 则将视觉 Token 与 LLM 的词表对齐,使图像可以直接作为 LLM 的输入来处理。
在音频 Tokenizer 领域,StableToken 引入了基于共识驱动机制的多分支架构,在多种噪声条件下显著提升了 Token 的稳定性,让语音 LLM 面对嘈杂环境时更加稳健。
一篇 2025 年的综述对离散 Tokenizer 的设计原则、应用和挑战进行了系统性梳理,涵盖了生成、理解、推荐和信息检索等多个领域,标志着 Tokenizer 正在从纯 NLP 技术演变为横跨多模态 AI 的基础组件。
五、实战指南:如何选择合适的 Tokenizer?
讲了这么多理论,最后来点“接地气”的内容——在实际项目中,该怎么选择和配置 Tokenizer?
5.1 场景驱动的选择策略
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 中文为主的应用 | SentencePiece (BPE) | 不依赖空格,中文适配好 |
| 英文为主的应用 | WordPiece 或 BPE | WordPiece 语义更精准,BPE 效率更高 |
| 多语言混合场景 | SentencePiece 或字节级 BPE | 语言无关,跨语言表现稳定 |
| 专业领域(法律/医疗) | 领域语料训练的 BPE + 词汇扩展 | 专业术语需要专门覆盖 |
| 低资源语言适配 | 词表替换 + 继续预训练 | 成本最低的适配方案 |
| 极致性能需求 | tiktoken(Rust 实现) | 推理速度最快 |
5.2 词表大小的选择
词表大小是 Tokenizer 训练中最重要的超参数之一。一般来说:
- 太小(比如 < 8000):导致每个词被拆得太碎,序列过长,计算量增加
- 太大(比如 > 100000):词表本身占用大量显存,且容易过拟合
主流 LLM 的词表大小通常在 32K 到 256K 之间。LLaMA 系列使用 32K,GPT-4 据说达到了 100K 以上。选择时需要权衡:对于多语言模型,词表应该大一些以覆盖更多字符;对于专业领域模型,可以适当缩小词表但提高领域词汇的覆盖率。
5.3 词汇扩展的工程实践
如果需要向已有模型添加新的专业术语(比如“量子计算”“神经网络”),可以使用以下方法:
# 使用 Hugging Face tokenizers 添加新词
new_tokens = ["量子计算", "神经网络", "transformer"]
tokenizer.add_tokens(new_tokens)
model.resize_token_embeddings(len(tokenizer))添加的 Token 会获得比 BPE 分词更高的优先级,从而保证专业术语不被错误拆分。
对于需要大规模更新词表的场景,可以考虑基于现有词表进行增量训练,生成新的合并规则文件,然后替换模型原有的分词配置。
六、总结与展望
6.1 Tokenizer 的“三重身份”
回顾全文,Tokenizer 在 LLM 体系中扮演着三重角色:
- 翻译官:将人类语言翻译成模型能懂的数字序列
- 守门人:决定哪些信息能进入模型、以什么粒度进入
- 公平性的守护者:不同语言的分词效率,直接影响着 AI 的全球可及性
一个设计得当的 Tokenizer,能够让模型训练更高效、推理更快速、跨语言能力更强;而一个糟糕的 Tokenizer,则可能让模型在面对生僻词、多语言混合文本、专业术语时捉襟见肘。
6.2 未来趋势一览
| 方向 | 代表工作 | 核心突破 |
|---|---|---|
| 多语言公平性 | Tokenization Disparities 研究 | 量化了 Tokenizer 对不同语言的计算不公平 |
| 通用多语言 Tokenizer | One Tokenizer To Rule Them All | 一个词表覆盖多语言,提升适应能力 |
| 词表适应 | AdaptBPE, VRCP | 不重新训练,让老词表学会新词 |
| 抛弃 Tokenizer | ByteFlow, Kathleen, MambaByte | 端到端字节级建模,不再需要静态词表 |
| 视觉/音频 Tokenizer | DualToken, TA-Tok, StableToken | 将离散 Token 扩展到多模态领域 |
作者
884705373@qq.com
相关文章