RAG 相关技术:从检索增强到可控知识注入
最近整理 AI 应用架构时,RAG 是绕不开的一块。它看起来像一个很朴素的办法:用户提问,系统去知识库里找几段相关材料,再把这些材料塞进 prompt,让模型基于材料回答。
但真正做工程时会发现,RAG 的难点不在“能不能搜到东西”,而在“能不能稳定地搜到对的东西,并让模型只用这些东西做出可检查的回答”。这篇笔记想把我对 RAG 相关技术的理解整理成一条链路:从知识如何被切分和索引,到检索结果如何被筛选、重排、压缩,再到回答如何被约束和评估。
RAG 解决的不是模型记忆,而是知识入口
我以前容易把 RAG 理解成“给模型外挂一个知识库”。这个说法没错,但有点粗。
更准确地说,RAG 是给模型提供一个可控的知识入口。模型本身有参数化知识,但这些知识有三个问题:更新慢、来源不可追踪、对私有业务知识不了解。RAG 把一部分知识从模型参数里拿出来,放到外部系统里管理:文档可以更新,来源可以追踪,召回过程可以记录,回答也可以回到证据上检查。
所以 RAG 的核心价值不是让模型“知道更多”,而是让模型在回答某个问题时,可以临时拿到一组和当前问题高度相关、来源明确、范围可控的材料。
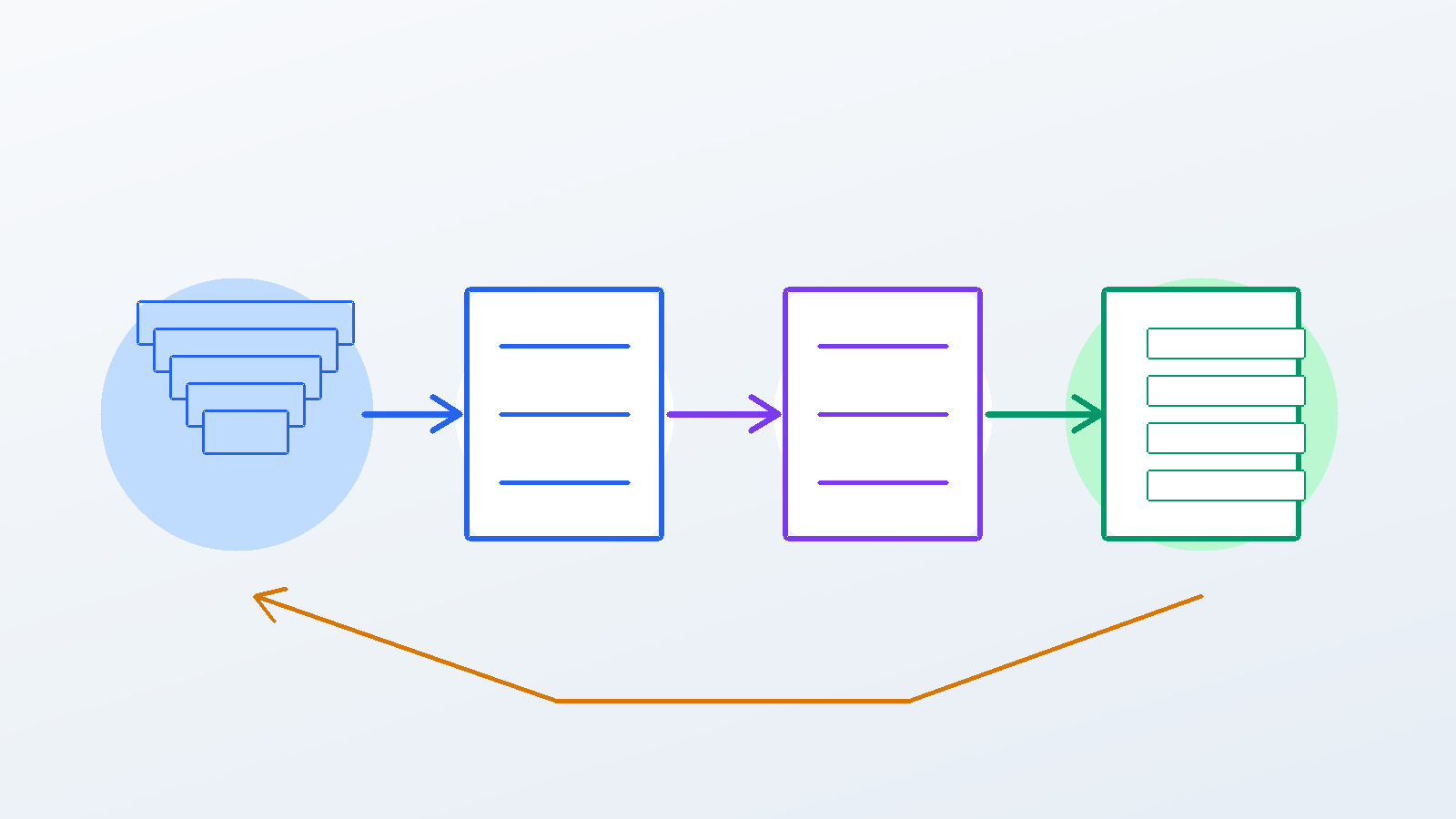
一个基本的 RAG 链路
我把 RAG 链路拆成两个阶段:离线建库和在线问答。
离线阶段通常从文档开始。系统会先解析 PDF、网页、Markdown、数据库记录或内部知识库,然后把长文档切成 chunk。chunk 的大小、重叠比例、标题和元数据会影响后面的召回效果。切得太大,检索结果不够精确;切得太小,片段会丢上下文。
接下来是向量化和索引。每个 chunk 会通过 embedding 模型变成向量,再写入向量库或托管的 vector store。为了后续过滤,通常还会保存文档来源、时间、部门、权限、标题、版本号等 metadata。这样线上检索时就不只是“语义相似”,还可以带上业务约束。
在线阶段从用户问题开始。系统先把问题改写或扩展成适合检索的 query,然后执行召回。召回可以是向量检索,也可以混合 BM25 这类关键词检索。拿到候选 chunk 之后,常见做法不是直接塞给模型,而是经过 reranking、去重、压缩和引用整理,最后再交给生成模型。
这个过程看起来长,但每一层都有明确目的:召回负责不漏,重排负责排序,压缩负责控制上下文成本,生成约束负责减少幻觉。
检索不只是向量相似度
向量检索是 RAG 的标志性技术,但它不是全部。
embedding 擅长捕捉语义相似。比如用户问“退款多久能到账”,系统可能召回“退货流程完成后 5 个工作日内原路返回”这样的片段,即使两句话没有太多相同词。这是传统关键词检索不容易做到的。
但关键词检索也有自己的价值。产品型号、错误码、人名、法规条款、接口字段名,很多时候需要精确匹配。纯向量检索可能会找到“语义上像”的内容,却错过真正包含关键字的文档。因此更稳的 RAG 往往是 hybrid retrieval:向量召回负责语义,BM25 或倒排索引负责精确词,最后用 rank fusion 或 reranker 合并结果。
Anthropic 提到的 Contextual Retrieval 也指向同一个问题:chunk 被切出来之后,可能丢掉文档级上下文。一个片段里写着“收入增长 3%”,但没有公司名和季度信息,检索和生成都会变得危险。解决思路是在 chunk 前补充由文档上下文生成的短说明,让它在 embedding 和关键词索引里都带上必要背景。
Reranking 是 RAG 的第二道闸
召回阶段通常宁可多拿一点候选结果,因为漏掉关键证据比多拿几个噪声更麻烦。但这些候选结果不能原样交给模型,否则上下文会变长,噪声会变多,回答也更容易被无关片段带偏。
reranking 的作用就是第二道闸。它不负责从全库里找东西,而是在候选集里重新判断“哪些片段对当前问题最有帮助”。这个判断可以用 cross-encoder、专门的 reranker 模型,也可以用轻量规则和 LLM 评分组合完成。
我觉得 reranking 的价值有三点:
- 把真正能回答问题的 chunk 排到前面。
- 降低相似但无用的材料进入 prompt 的概率。
- 让 top-k 的选择更有弹性,而不是固定拿前 5 段或前 10 段。
近一年很多 RAG 讨论都围绕动态重排、上下文压缩和自适应 top-k 展开,本质上都是在解决同一个矛盾:材料太少会漏证据,材料太多会引入噪声和成本。
生成阶段要有边界
RAG 最后一步是生成,但生成不是简单地把检索结果拼到 prompt 里。
一个可控的 RAG prompt 至少要告诉模型几件事:哪些内容是可用证据,用户问题是什么,回答应该遵守什么格式,遇到证据不足时应该怎么说,是否需要引用来源,是否允许根据常识补充。
这里最容易出错的是“检索到了材料,所以回答一定可靠”。其实不一定。检索结果可能不完整,可能过期,可能互相冲突,也可能只回答了问题的一半。好的 RAG 系统应该允许模型说“现有资料不足以判断”,而不是强行编一个完整答案。
这也是我理解的 RAG 和普通 prompt engineering 的区别:RAG 不只是 prompt 里多了一段 context,而是把“证据从哪里来、证据是否足够、回答是否忠于证据”变成系统的一部分。
Agentic RAG:让检索变成多步动作
传统 RAG 往往是一问一搜一答。Agentic RAG 则更像一个小型调查流程:模型可以先分析问题,再决定查哪些索引、用哪些过滤条件、是否需要改写 query、是否需要二次检索,最后再综合回答。
这种方式适合复杂问题。比如用户问“过去两版产品文档里,权限模型变化对企业客户有什么影响”,单次检索很可能不够。系统可能需要先找版本说明,再找权限文档,再找企业配置示例,最后比较差异。
但 Agentic RAG 也更需要约束。检索步骤越多,越要记录每一步 query、命中的文档、选择或丢弃的原因。否则它会变成另一个黑箱:看起来做了很多搜索,但最后仍然不知道答案为什么可信。
RAG 的评估不能只看最终回答
评估 RAG 时,只看最终答案是不够的。因为错误可能发生在任何一层。
如果没有召回正确文档,是 retrieval 问题;如果召回了但排在后面没进上下文,是 reranking 或 top-k 问题;如果材料进了上下文但模型没有用,是生成约束问题;如果材料本身过期或冲突,是知识库治理问题。
所以我更倾向于把 RAG 评估拆成几类指标:
- 召回指标:正确证据是否进入候选集。
- 排序指标:正确证据是否进入最终上下文。
- 忠实度指标:回答是否被证据支持。
- 可用性指标:回答是否解决用户问题。
- 成本指标:检索、重排、上下文长度和延迟是否可接受。
这些指标不一定都要自动化,但至少应该在日志里保留足够信息,让失败可以复盘。
我对 RAG 工程化的理解
RAG 的工程重点不是“接一个向量数据库”,而是把知识流转过程做成一条可观察的链路。
文档进入系统时,要知道它从哪里来、属于谁、什么时候更新、谁能访问。文档被切成 chunk 时,要尽量保留标题、章节、上下文和元数据。检索时,要同时考虑语义相似、关键词精确匹配和权限过滤。重排时,要控制噪声进入 prompt。生成时,要明确证据边界。发布或落地时,要能解释答案来自哪些材料。
这样看,RAG 更像知识系统和生成模型之间的一层协议。它既不完全属于搜索,也不完全属于大模型,而是在两者之间负责把“外部知识”变成“模型可用、用户可信、系统可控”的上下文。
小结
我会用五句话总结这次对 RAG 的理解:
- RAG 是可控知识入口,不是简单外挂记忆。
- chunk 设计决定了知识能不能被正确召回。
- hybrid retrieval 和 reranking 是提升稳定性的关键。
- 生成阶段必须有证据边界和不足时的退路。
- 真正可靠的 RAG 要评估整条链路,而不是只评估最终回答。
如果说大模型提供的是语言和推理能力,那么 RAG 提供的就是可更新、可追踪、可治理的知识通道。两者结合得好,AI 应用才更接近可维护的软件系统,而不是一次性的问答界面。
作者
884705373@qq.com
相关文章