如果说我们之前拆解的所有Transformer组件——从FFN到Attention——都是为了让单个模型更“聪明”,那么今天我们要聊的MoE(Mixture of Experts,混合专家)架构,就是一次彻底的“组织形式”革命:既然一个大脑不够用,那为什么不请一个“专家组”来协同工作呢?
MoE打破了“一个模型,一次全部激活”的规则。它让模型在面对不同问题时,能够有选择性地、动态地只激活一小部分最相关的“专家”参数,这不仅让模型拥有了极其庞大的“专家团”(总参数量),同时又将实际的计算开销控制在了可接受的范围内。
一、MoE核心思想:用查字典的方式调用模型
1.1 从“百科全书”到“专家会诊”
稠密模型就像一个随身的“百科全书”,每当处理一个Token(词元),都需要翻遍整本书的所有页面(所有参数)。虽然知识详尽,但每次查找的代价都很高。这导致模型的“知识量”(参数规模)和“查找速度”(计算开销)被强行绑定在一起。
MoE模型的思路则很巧妙:与其随时带着整套百科全书,不如组建一个 “专家会诊团” 。当遇到问题时,先由一位知识广博的 “分诊台护士”(即路由器,Router,或门控网络,Gating Network) 快速判断问题的性质,然后将问题精准地分派给1到2位最相关的 “专家”(Expert) 。
每个专家可以看作是一个缩微版的“领域百科”——它们在结构上与我们熟知的FFN类似。最终,模型只激活被选中专家的参数进行计算,并将它们的建议融合输出,而无需惊动整个庞大的专家团。这样一来,模型能在拥有海量知识储备的同时,保证每一次“会诊”的高效。
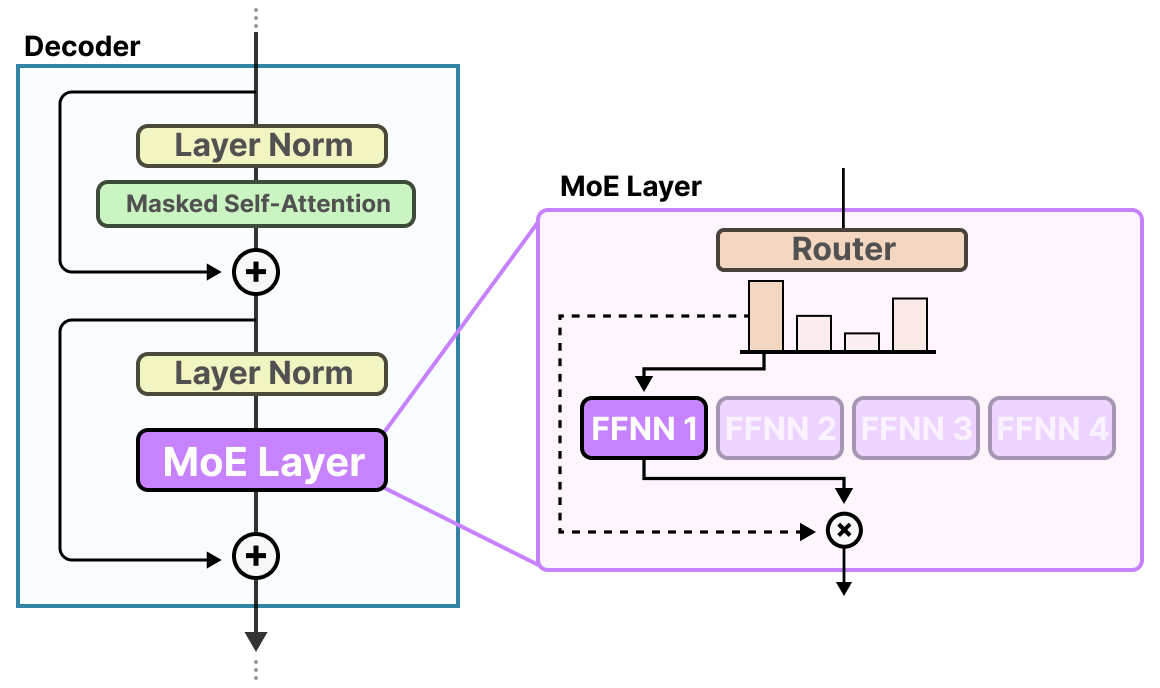
1.2 专家与路由器的结构
在MoE层(通常替换掉Transformer Block中的标准FFN层)中,“专家”本质上就是一个 前馈网络(FFN) 。一个MoE层会包含多个这样的专家,并且它们会均匀地分布在不同的GPU上,这种方式被称为专家并行(Expert Parallelism) ,能有效分摊巨大的显存压力。
路由器通常是一个轻量级的、可训练的线性层。它的任务是为当前输入的Token向量,计算出一个分配给所有专家的“匹配度”分数。
二、路由:谁来决定专家的“排班表”?
如果说专家是MoE的执行者,那么路由(Routing)策略就是决定系统效率与公平的核心大脑。一个好的路由机制,不仅要“分得准”,还要“分得匀”。
2.1 主流模式:Token“选择”专家(Token Choice)
这是目前最主流的方法,它的核心逻辑是:让每个Token自己去挑选它认为最合适的Top-K个专家。
绝大多数顶尖的MoE模型,如Qwen、DeepSeek、Mixtral等,都采取这种方法,并且通常设置K=2(即Top-2 routing)。计算流程如下:
- 路由打分:输入Token
x,轻量级路由器为每个专家e计算出一个初始分数s_e(路由器输出logits)。 - Softmax归一化:将分数转化为0到1之间的概率
g_e。 - Top-K选择:保留概率最高的K个专家的权重,其余专家的权重设为0。
- 加权聚合:将输入Token分别送入选中的K个专家网络中,然后将它们的输出按照归一化后的权重加权求和。最终的输出会加回原始的残差流中。
值得注意的是,有研究表明,即使使用毫无语义的哈希函数进行路由,MoE也能带来性能提升,这说明了“条件计算”本身的价值。
2.2 另辟蹊径:专家“选择”Token(Expert Choice)
这是一种完全相反的思路,它能从根本上解决负载不均的问题:赋予专家“反向选择权”,让每个专家从候选Token中挑选自己最擅长的Top-K个Token进行处理。
这种方法可以保证每个专家的计算负载是完全均衡的。然而,它也存在明显的缺点:一个Token可能会被多个专家选中,导致重复计算;也可能完全被所有专家忽略,变成“孤儿Token”,影响模型性能。因此,虽然在理论上很有吸引力,但在工程实现上更为复杂,应用不如Token Choice广泛。
2.3 Token Choice的固有缺陷与应对
尽管高效,但纯粹的Token Choice,最终会导致“富者愈富”的赢家通吃问题,或我们熟知的马太效应(Matthew Effect) 。少数几个“明星”专家会因频繁被选中而过载,而大部分专家则被闲置,这不仅造成了算力浪费,还会由于路由过于集中而损害模型的性能。
为了解决这个问题,必须引入一套“宏观调控”手段——负载均衡(Load Balancing)。
三、负载均衡:如何防止专家“忙闲不均”?
负载均衡是确保MoE模型高效运转的两大关键技术之一。
🛠️ 关键技术①:设置专家容量(Capacity)
为了防止单个专家被海量Token淹没,每个专家会被设定一个处理上限,即 “专家容量”(Capacity)。其计算公式为:
每个专家的容量 = (每批Token总数 / 专家数) × 容量因子(Capacity Factor)
- 容量因子是一个大于1的系数(例如1.25),它为专家处理能力的波动提供了一个“缓冲区”,避免因流量小高峰就导致丢弃Token。
所有超出专家容量的Token都会被直接“丢弃”(跳过该MoE层),直接通过残差连接传递至下一层。尽管粗暴,但这是维持系统稳定运行的必要代价。
🛠️ 关键技术②:添加辅助损失(Auxiliary Loss)
在训练阶段也会通过向总损失函数中添加一个精心设计的 “负载均衡损失”(Load Balancing Loss) ,来鼓励路由器更加“公平”地分配Token。这个辅助损失的核心是惩罚过高的路由集中度。目标是引导模型学习一个更加均匀的Token分配策略,让所有专家都能“有事可做”。
然而,2025年的最新研究提出,强迫专家学习均匀分配的策略,反而可能导致专家为了应付更多Token而学习相似的通用知识,从而偏离了专业化的初衷,造成 “知识冗余” 。这给MoE的发展带来了新的课题。
四、深度进化:MoE走向成熟的三大技术飞跃
随着研究的深入,学术界和工业界对经典MoE的短板有了更清晰的认识,并由此催生了新的解决方案。
🚀 经典MoE的两大困扰:知识混杂与冗余
在早期的MoE架构中,专家的数量通常不多(例如8个或16个)。这导致了两个棘手的问题:
- 知识混杂:单个专家被迫学习跨度极大的知识,导致其难以真正“专精”。
- 知识冗余:不同的专家都需要掌握一些共有的基础能力,导致参数被大量浪费。
为了应对这些挑战,MoE技术在实践中发展出了三大关键:
🚀 技术飞跃①:细粒度专家
这项技术可以看作是在“专家”层面也运用了“分而治之”的思路。在保持总参数量和总计算量不变的前提下,将一个大的专家切分为多个更小的“细粒度专家”,同时增加激活专家的数量。这样一来,每个专家可以处理的知识范围变得更窄、更专业,有效缓解了知识混杂的问题。
其核心创新在于打破了专家数量与激活专家数量的严格绑定,用一个激活的专家组合取代了原来的大专家,实现了更为灵活的“专家重组”。
🚀 技术飞跃②:共享专家
为解决知识冗余问题,共享专家(Shared Expert) 应运而生。
DeepSeekMoE团队提出了“共享专家隔离”的策略。模型的每一层会专门划分出少数几个“共享专家”,这些专家始终被激活,用以捕获和处理在所有上下文中都可能出现的通用知识(如基础语法、常用词汇等)。这样,那些被选择性激活的“路由专家”就能彻底从这些“基础事务”中解放出来,专注于学习更深层次、更专业的知识。
实验证明,这项策略极为有效。在DeepSeekMoE 16B模型中,共享专家在情感分类、文本摘要等任务中的激活概率普遍较高,为模型快速、准确地处理通用知识提供了强有力支撑。
🚀 技术飞跃③:归一化Sigmoid门控
DeepSeekMoE还引入了归一化Sigmoid门控,用sigmoid函数计算每个专家的分数,再进行全局归一化。相比Softmax,Sigmoid的输出是互相独立的,有效避免了Softmax容易导致的“赢家通吃”问题,进一步提升了专家利用率和训练稳定性。
五、分布式训练:专家并行的机遇与瓶颈
MoE的“稀疏激活”特性使其能容纳海量参数,但也带来了独一无二的分布式挑战。
5.1 专家并行
将不同的专家分布到不同GPU上,被称为专家并行。在前向传播时,路由器需要将每个Token发送到它所选中的专家所在的GPU上。这需要一次全球范围的 All-to-All 通信来进行数据交换。在大规模集群中,这种跨节点通信的开销,往往会成为制约训练效率的瓶颈。
5.2 混合并行:全方位多维优化
为了解决单一并行策略的瓶颈,工业界已将专家并行与其他三种并行策略深度结合,形成四维或五维混合并行:
- 数据并行(Data Parallelism):在不同设备上处理不同批次数据,反向传播时同步梯度。
- 张量并行(Tensor Parallelism):将单个层的大矩阵切分到多个设备并行计算,降低单卡显存压力。
- 流水线并行(Pipeline Parallelism):将不同层分配到不同设备,形成流水线处理。
- 上下文并行(Context Parallelism):将长上下文序列切分到不同设备,降低Attention复杂度。
更值得关注的是,Nvidia提出的MoE并行折叠(MoE Parallel Folding) 策略,关键创新在于解耦Attention层与MoE层的并行配置,让特定类型层能采用最优并行策略。最终实现了针对8x22B模型高达49.3%的MFU(模型FLOPs利用率)。
5.3 高效通信:系统加速引擎
All-to-All的巨大通信开销使得算法的加速极其依赖系统级创新。
- UniEP超级内核:通过将MoE的通信与计算熔合进一个“超级内核”(MegaKernel),减少数据搬移,实现了1.03-1.38倍的加速。
- 低精度通信:将通信时的数据精度从高精的BF16降为FP8,精确权衡后带来10%-25%的吞吐量提升。
可以看出,未来的MoE比拼,除了算法本身,更考验体系结构的深刻理解。
六、总结与展望:迈向稀疏智能的新时代
6.1 MoE架构的演进路线
回顾MoE的发展,清晰的技术跃迁指向着极致的“专业化”和“效率化”:
| 阶段 | 代表模型/技术 | 核心贡献、突破及指标 |
|---|---|---|
| 1.0 基础构建 | Switch Transformer, GShard | 奠定稀疏MoE路线,验证Top-K路由与辅助损失有效性,实现参数与计算解耦 |
| 2.0 高效稳定 | ST-MoE, Mixtral, Qwen/MoE | 优化容量限制与Token丢弃;引入路由器z-loss等;稳定千亿级参数训练 |
| 3.0 极致专业化 | DeepSeekMoE | 细粒度专家+共享专家,缓解了知识混杂与冗余;为DeepSeek-V3等顶尖模型铺路 |
| 4.0 系统深度融合 | MoE并行折叠, UnieP | 解耦并行策略,MFU达49.3%;熔合MegaKernel,持续刷新效率 |
6.2 串联系列知识:MoE架构所扮演的“角色”
在我们构建的LLM知识体系中,MoE的角色已清晰明了:
- 历史文章回顾:
- Tokenizer → Embedding → RoPE(位置编码) → Attention机制(MHA/MQA/GQA)
- Pre-Norm & Post-Norm(稳定与深度)→ KV Cache(推理核心)
- MoE架构(我们在此处!):FFN的“专家矩阵”版,继承了FFN的“知识存储器”角色,并使用GQA作为注意力
目前,几乎所有领先的大模型,如DeepSeek-V3、Qwen2.5-VL、Gemini-2.5等,都已将MoE作为核心架构。
6.3 前沿探索一览
- 摒弃路由器的探索:如MoDE等研究发现,相比复杂的可训练路由器,简单的哈希等随机方法也能达到不错效果且更稳定,这对昂贵的大规模预训练极具启发性。也有工作尝试用最优传输(Optimal Transport) 求解全局最优匹配。
- 推理时动态跳过:如MoDEs通过全局重要性估计,在推理时跳过88%激活专家,保留97%性能,实现近2倍加速,展现专家选择的巨大优化空间。
- 通用路由进化:被TensorFlow等框架评估的Dense Backpropagation等新路由器方案,旨在根本上改进传统Top-K路由。
- 激活稀疏性利用:如2026年的MoC(Mixture-of-Channels) 观察到SwiGLU原生的激活稀疏性,可无需路由网络实现动态稀疏,降低激活内存占用。
- 可解释性新视角:从聚焦单个“专家”,转向关注专家“轨迹”(Expert trajectories) 。尽管专家可能多义,但跨层路由轨迹却高度一致,提升了模型决策的可理解性。
MoE已不仅是算法层面的创新,它更深度地改变了底层系统和硬件设计,为软、硬一体的协同优化提供了全新空间。正是得益于MoE,我们才能在今天用更少的算力,驱动着一个智力密度更高的模型。
作者
884705373@qq.com
相关文章