写在前面
目前为止的文章都在聊一件事:单个模型内部的“微观世界” ——Embedding怎么工作、Attention怎么计算、FFN怎么存储知识、MoE怎么调度专家。但我一直在一个默认假设下讲故事:模型能完整装进一台GPU。
现实当然不是这样。今天的大语言模型动辄上千亿参数:一个7B模型就已经吃掉约14GB显存(FP16格式下仅参数权重部分),而70B模型直奔140GB。单张H100最高也只有80GB显存,放大模型后连一张卡都装不下。更别说训练时还要额外存梯度、优化器状态和中间激活值——这些辅助数据的显存需求往往是模型参数量的好几倍。于是,我们不得不用成百上千张显卡来协作。
这件事听起来简单:“多放几张卡不就行了?”真的做起来,难题接踵而来:模型怎么切?数据怎么分?卡和卡之间怎么“沟通”?聊天太频繁会堵住,聊太少会算错,乱聊天会崩。
今天的文章就是要讲清楚:工业界到底用什么方法把一台装不下的模型,拆到几百几千张卡上训练,又要快又要稳。这个领域目前公认的“三板斧”正是——数据并行(Data Parallelism)、张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),三者组合在一起,就是现代大模型训练的“3D并行”核心架构。
读完这篇文章,你会明白为什么训练Llama-70B需要几百张H100,以及那三个字母缩写的背后各自在解决什么问题、各自又有什么先天不足。
一、数据并行:最直观的“人多力量大”
1.1 原始直觉与标准流程
数据并行是最先被想到的方案:模型本身能不能放进GPU不重要,先把模型完整复制到每一张卡上,然后把训练数据切碎,每张卡各自吃一小份。每张卡在“相同的模型副本”上分别计算梯度,最后把所有人的梯度汇总起来求一个平均,用这个“平均梯度”去统一更新各张卡上的模型参数。
具体流程是:
- 复制模型:将完全相同的模型副本加载到每张GPU上。
- 分发数据:将一个Batch的训练样本均匀分成若干Micro-Batch,每张卡处理其中一份。
- 独立计算梯度:各GPU独立完成前向传播和反向传播,算出各自的局部梯度。
- 通信同步梯度:执行All-Reduce通信,把所有GPU的梯度汇总成全局平均梯度。
- 同步更新参数:每张GPU用这个全局梯度统一更新本地模型参数。
从效果看,数据并行直接“并行放大”了训练吞吐量。它也是目前实现最简单、应用最广泛的分布式训练方式。
1.2 看似完美的代价:膨胀的通信与冗余的参数
数据并行的核心问题可以用一个词概括:冗余。模型必须被完整复制到每张卡上,导致一个直接的矛盾:所有GPU的总显存加起来可能非常大,但每张卡能看到的“有效显存”仍受限于单卡容量。70B的模型要FP16存储,单卡不够就是不够,加再多卡也无济于事。
另外一个隐形问题是通信开销。每一次梯度同步都需要执行All-Reduce操作,其所传输的数据量相当于模型参数量。当GPU数量增多、模型参数不断膨胀时,同步通信可能会耗时数十毫秒甚至上百毫秒,成为巨大的性能瓶颈。所以数据并行虽然是必选项,但在训练巨型模型时绝不可能“单打独斗”。
1.3 优化思路:梯度累积与通信-计算重叠
针对数据并行的通信瓶颈,常见的一类优化是梯度累积:不一定要每个Micro-Batch结束就立刻执行All-Reduce,可以让每张卡独立计算若干个Micro-Batch后,把梯度累加起来,再统一做一次通信同步。这样一来,有效全局Batch Size没有变,但通信频率大幅降低。
另一类优化是在底层实现上做“通信-计算重叠”:用PyTorch DDP内置的async_op=True等机制,在反向传播计算最后一层的同时,提前启动底层通信链路传输已就绪的梯度张量,把通信开销“藏”在计算时间里。
不过,无论怎么优化,数据并行的根本限制没有消失:当单卡显存根本放不下完整模型时,它必须与其他并行方式协同作战。
二、张量并行:当模型本身就大到要“撕开”
2.1 核心思想:把权重矩阵切成“平行碎片”
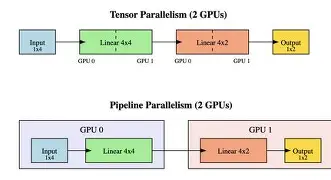
当Transformer里的一个矩阵乘法本身就大到连一层都塞不进一张卡时,就必须用更细粒度的切法——张量并行(Tensor Parallelism, TP) 就是用来解决这个问题的技术。
张量并行的核心是把单个层的权重张量(如大的线性层参数矩阵W)沿着特定维度切分成多份,分别放到不同GPU上,每个GPU只保存一部分权重。以X × W为例:X是输入张量(维度[Batch, SeqLen, HiddenSize]),W是权重张量(维度[HiddenSize, HiddenSize’])。在单卡上,这个乘法能够直接完成。但如果W实在太大了,需要在多张卡上“联合计算”,主要有两种经典切法:
按行切分:沿W的行维度把W切成几份。切W的行后,输入X也需要按列对齐切割。每张卡拿分片后的X和W先各自做矩阵乘法,得到部分结果Y_partial;然后执行All-Reduce通信,把各卡的部分结果求和到每个GPU上,得到完整输出Y。
按列切分:沿W的列维度把W切成几份。输入X因为列维度应和W切分后的行维度对齐,所以可以直接Broadcast到各个GPU。每张卡得到完整X后和W的分片X相乘,得到局部分片输出Y_partial;最后把所有Y_partial沿最后一个维度拼接,全部汇总即可得到完整输出Y。
这两种切法在Megatron-LM等主流框架中就是最基础的操作单元。LLaMA、Qwen、DeepSeek等大模型中几乎所有的超大矩阵乘法,都是用这两种切法及其组合来实现的。
2.2 代价:通信变得又密又精细
张量并行每一层算完都要通信——All-Reduce或All-Gather——而且通信的数据量和切分方案密切相关。每两层之间同步一次,导致通信访存量远大于数据并行。而且因为涉及还原完整的计算图,TP的错误实现会导致隐藏Bug式的精度下降,这也是为什么张量并行通常被认为是实现最复杂的大模型训练方法之一。
工业界的实践是:张量并行只用在单机内部的高速互联(如NVLink、NVSwitch)上。跨机网络(如RoCE、InfiniBand)带宽远低于机内,做TP会让通信开销吞噬掉所有加速收益。
三、流水线并行:用“工厂流水线”串起大模型
3.1 基本思想:按层排队,像工厂流水线分配工作
流水线并行把模型按层(Layer)切分开,每张卡或每个设备负责一段连续的“Stage”(层区间)。数据像流水线上的零件一样依次从第一张卡流到最后一张卡:第一张卡完成自己的层的计算后,把中间结果传给下一张卡;下一张卡接着算,直到最后一层吞吐出结果。
但原始流水线有一个本质问题:流水线气泡(Pipeline Bubble)。如果把数据一次性完整跑完前向传播再做反向传播,每张卡计算任务启动和结束的时间差会导致大量卡处在空闲等待状态,利用率极低。
于是研究者发现,解决问题的关键就在于:把一个Batch拆成多个Micro-Batch。
3.2 从GPipe到1F1B:消灭气泡的演进之路
GPipe是微软在2018年最早系统提出Micro-Batch概念的工作。它的贡献在于首次找到了一个干净利落消灭流水线气泡的方案:把一个Data Batch切成m个Micro-Batch,让它们紧密排队经过流水线Stage;所有Micro-Batch的前向传播全部完成后,再统一进入反向传播。这个方案让每个GPU在绝大部分时间内都有活干,气泡被压缩到最小。
PipeDream(1F1B策略) 做了进一步优化:它不再等待所有Micro-Batch的前向传播完成再统一做反向传播,而是每完成一个Micro-Batch的前向传播,只要对应的后向计算条件满足,就立刻插入一次反向传播。这样一来,反向传播的计算和前向传播大量重叠,进一步提高了整体吞吐量。
此外,虚拟流水线并行(VPP) 等策略通过在一个Stage内部进一步切分计算任务,继续精细化填充气泡,使GPU利用率无限逼近100%。
3.3 优与劣:跨层通信非常少,但配置难度高
流水线并行的最大优势在于:通信只在相邻Stage之间发生,每一个Step只需要传递一次张量,通信体积极小,天然适合跨机通信不足的场景。很多千亿乃至万亿稠密模型的训练,都把流水线并行作为主要的跨机切分方式。
流水线最大的挑战是启动时的“空闲尾部”和显存不对称。不同Stage的显存占用天然不同:靠前的Stage往往存了更多的激活值,导致整条流水线的显存利用率参差不齐。负载均衡是流水线设置中最头疼的问题。此外,如果多个Stage恰好落在不同物理节点上,节点间通信的质量会严重影响流水线效率。工业界通常的做法是人工或半自动地将流水线与网络拓扑绑定:确保连续的Stage尽可能放在同一台物理服务器内。
四、3D并行:把三种方法“拧成一股绳”
4.1 一个统一的框架
到了2019年后,大模型训练领域凝聚出一个共识:对于超大模型,单靠一种并行策略是不够的。于是数据并行、张量并行、流水线并行被统一配置在同一个训练任务里,形成所谓“3D并行”。
具体配置逻辑通常是:
- 张量并行(TP):用在单机内部,打破超大矩阵乘法。
- 流水线并行(PP):用在跨机之间,把庞杂的层序列拆成多段。
- 数据并行(DP):作用在整个集群上,用冗余数据副本提高吞吐量。
OpenAI的GPT-3、NVIDIA的Megatron-Turing NLG 530B,以及后来的LLaMA-70B/400B,全部是在这个框架上跑出来的。DeepSeek-V3在3D并行的基础上还叠加了专家并行(Expert Parallelism),形成了五维并行结构。
4.2 为什么混合并行是“刚需”?
用一张卡车队的类比来说明:数据并行就像一个公司每一辆卡车的型号和运力完全相同,可以同步装卸货,但在超大货物面前所有车都“放不下”。张量并行相当于把单个超大货物在工厂里就提前拆解,分别用更多车装。流水线并行则建立了从包装车间到配送中心的垂直流水线,把步骤拆开。三者协同,货物本身就会在不同的维度以不同精度被拆分,最终每条传送带上的车都装得下、跑得动。
实践证明,这种多维度协同的收益巨大:DeepSeek-R1在32节点集群(每节点8卡A100)使用3D并行加ZeRO-3优化后,相比纯数据并行方案,内存占用降低62%,通信开销减少41%。
五、前沿演进:DP的“接班人”与并行的新维度
三种基础并行策略建立后,整个领域的前沿方向一直在扩展新的维度。
5.1 零冗余数据并行(ZeRO)
ZeRO从根本上回答了“数据并行的显存冗余能否被消灭”的问题。它把传统数据并行中每张卡都要完整保存三份数据——模型参数、梯度、优化器状态——的“全员复制”模式拆解为分布式切分:
- ZeRO-1(优化器状态分片):只分片优化器状态。
- ZeRO-2(梯度+优化器状态分片):梯度也分片存放。
- ZeRO-3(全部模型状态分片):从前向传播中计算出的每一块模型参数和激活值,按需要临时收集,用完立即释放“借用”的空间。
ZeRO几乎消除了数据并行的内存冗余,让单卡上无法承载的模型可以通过多卡数据并行训练得以实现。其升级版本ZeRO++引入了量化通信等技术,将通信量降至1/4,吞吐提升至原来的2.16倍;ZeRO-Offload 等变体则可以在训练中动态将部分数据暂存在CPU内存或NVMe硬盘上,进一步打破物理显存限制。
5.2 序列并行与上下文并行
随着大模型的上下文长度从4K向128K甚至1M扩展,“Activation激活值”成为比参数更夸张的显存占用来源。激活显存和序列长度呈线性正相关,超长序列会导致单卡即使装得下模型也装不下中间激活。
序列并行(Sequence Parallelism) 把输入序列沿序列长度维(splitting by seq_len)切分到多张卡上并行计算,LayerNorm、Dropout等逐序列操作天然可以分片。这一技术与张量并行搭配时能极大降低激活值内存压力,成为近年超长序列训练的标准实践。
上下文并行(Context Parallelism) 则是把注意力层Q、K、V切长序列,用Ring Self-Attention等方式避免构建完整的N×N长Attention矩阵,支持训练百万Token长度的序列。
5.3 自动并行与自适应调度
手动配置并行策略需要极其丰富的先验经验,人脑很难算出TP=4、PP=8、DP=64且显存不爆的最优组合。2025年后,领域里出现了一些自动化搜索并行配置的工作——给定模型结构和硬件集群信息,自动计算出最优的混合并行策略及其资源分配,在训练吞吐上获得远超人工设定的收益。
六、三条路径的“核心差异”
| 维度 | 数据并行(DP) | 张量并行(TP) | 流水线并行(PP) |
|---|---|---|---|
| 切分对象 | 数据(沿Batch切分) | 每一个权重张量(按维度切分) | 模型层(按Stage切分) |
| 每卡拥有 | 完整模型副本 | 每个大矩阵的局部切片 | 一个连续的层区间 |
| 通信密集度 | 每Step同步(All-Reduce) | 每层内多次通信 | Stage边界极少量通信 |
| 实现复杂度 | 极低 | 最高 | 较高(需配置气泡) |
| 适合的硬件拓扑 | 跨机可接受 | 必须机内高速互联 | 跨机/节点完美契合 |
| 适合的模型规模 | 小模型,或已有ZeRO支援 | 真正重量级矩阵乘法 | 千亿、万亿稠密层模型 |
| 主要瓶颈 | 通信、显存冗余 | 通信延迟,计算和通信强耦合 | 气泡、负载不均、激活带宽 |
七、总结与展望:3D并行之后,还有什么新故事?
数据并行、张量并行、流水线并行三者构成了现代大模型训练分布式系统最经典的“三板斧”。从早期的各做各的,到如今被有机融合到统一的“3D并行”框架,它们不仅解决了算力规模化的问题,更反过来深刻影响了大模型的设计哲学——MoE的出现就是在算法层面主动回答了一个问题:“如何在一个分布式的世界实现更高的计算专门化。”
展望未来,多个前沿方向正在推进:
- 自动搜索最优混合并行策略:从人脑设置到系统优化的范式转移,Galvatron等框架已实现动态选择并行策略。
- 算存分离架构与异构内存交换(ZeRO-Offload与SSD/NVMe加速) :进一步把模型状态扩展到CPU甚至SSD上,用计算换显存。
- 专家并行、图像并行、多模态的大规模并行训练:在MoE和视觉模型中增加了新的并行维度,与3D并行并立形成4D/5D混合并行。
- 异构芯片的全球化调度:将同一训练任务跨不同算力、不同互联速度的GPU协同调度成最优分布态。
串联系列知识总结
我们目前走过的路线:
- Tokenizer → Embedding → RoPE
- Attention(MHA/MQA/GQA) → FFN(SwiGLU)
- Pre-Norm / Post-Norm / 残差连接
- MoE架构(专家与路由机制)
- KV Cache与PagedAttention
- 数据并行、张量并行、流水线并行(本文)
作者
884705373@qq.com
相关文章